Feature selection using target permutation (Null Importance)
아래의 글은 Olivier의 feature selection with null importances를 번역한 글입니다.
논문
원문 링크
이 Notebook 파일은 다음의 논문 를 토대로 만든 자료입니다. kaggle의 Home Credit Default Risk 라는 대회에서 변수 제거를 하기 위해 만들어진 커널 입니다.
Null Importance Feature Selection:
- 실제 변수의 중요도와 임의로 셔플된 목적변수의 변수중요도의 분포를 비교하는 방법입니다.
-
장점:
- 변수들끼리의 상호작용 중요성을 없애지 않습니다.
- 높은 분산을 가지거나 목적변수와 연관이 없는 변수들을 쉽게 찾을 수 있습니다.
Notebook의 시행 과정:
-
Null importance 분포를 만듭니다 : 이 분포는 목적변수를 임의로 섞음으로써 만들어집니다. 이 분포는 목적변수에 관계없는 변수를 모델이 어떻게 이해하는지 보여줍니다.
-
먼저 기존의 목적변수에 따른 변수의 중요도를 수집합니다. : 이 중요도는 Null importance 분포와 비교를 할 수 있게 해주는 벤치마크 역할을 해줍니다.
-
각각의 변수들에 대해 실제 중요도 평가합니다 :
- Null importance에 대한 실제 중요도의 확률값을 계산합니다. 논문에서 제안된 수집 된 데이터에 알려진 분포를 맞추기 위한 매우 간단한 추정을 사용합니다. 실제로 여기서 목적변수가 1이 될 확률을 계산할 것입니다.
- 실제 중요도를 null importance의 평균 및 최대치와 간단히 비교합니다. 그러면 데이터 세트의 주요 기능변수을 볼 수 있을 것입니다. 실제로 앞의 방법은 우리에게 많은 것들을 줄 수 있습니다.
데이터의 전처리 시간상의 이유로, 커널에서는 application_train.csv만을 다룹니다. 하지만 실제 사용시에는 모든 데이터를 포함해서 사용하기를 바랍니다. (옮긴 이 : Home Credit Default Risk 대회에서는 총 6개의 data set이 주어지고 FE 과정까지 거치면 1,000개가 넘는 변수가 생겼습니다. 변수가 너무 많은 문제 때문에 변수 제거 방법에 대한 논의가 많이 이루어졌고, 이 대회에서 사람들이 많이 사용했던 방법이 Null importance 방법입니다. ) 아래에서 부터는 코드와 함께 Null Importance Feature Selection에 대해 설명하도록 하겠습니다.
패키지 불러오기
import pandas as pd
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import KFold
import time
from lightgbm import LGBMClassifier
import lightgbm as lgb
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import seaborn as sns
%matplotlib inline
import warnings
warnings.simplefilter(`ignore`, UserWarning)
import gc
gc.enable()데이터 불러오기
데이터를 읽고 카테고리 데이터의 전처리를 해줍니다.
data = pd.read_csv(`application_train.csv`)
categorical_feats = [
f for f in data.columns if data[f].dtype == `object`
]
categorical_feats
for f_ in categorical_feats:
data[f_], _ = pd.factorize(data[f_])
# 카테고리변수의 타입을 categoty로 설정하여줍니다.
data[f_] = data[f_].astype(`category`)data.head()평가 함수 만들기
LightGBM의 random forest boosting을 사용하여 평가함수를 만들어줍니다.
def get_feature_importances(data, shuffle, seed=None):
# 실제로 사용할 변수들을 모아줍니다. 목적변수('TARGET')는 y 값이어서 빼고, SK_ID_CURR는 식별자여서 제거합니다.
train_features = [f for f in data if f not in [`TARGET`, `SK_ID_CURR`]]
# fold 방식을 사용해서 CV score와 변수 중요도를 기록합니다.
y = data[`TARGET`].copy()
# 필요하면 목적변수를 섞어줍니다.
if shuffle:
# 여기에서 이항 분포를 사용할 수도 있습니다.
y = data[`TARGET`].copy().sample(frac=1.0)
# LightGBM에서 random forest 타입을 사용합니다. (sklearn의 random forest보다 빠릅니다.)
dtrain = lgb.Dataset(data[train_features], y, free_raw_data=False, silent=True)
lgb_params = {
`objective`: `binary`,
`boosting_type`: `rf`,
`subsample`: 0.623,
`colsample_bytree`: 0.7,
`num_leaves`: 127,
`max_depth`: 8,
`seed`: seed,
`bagging_freq`: 1,
`n_jobs`: 4
}
# 모델을 학습시킵니다.
clf = lgb.train(params=lgb_params, train_set=dtrain, num_boost_round=200, categorical_feature=categorical_feats)
# 변수중요도를 기록합니다.
imp_df = pd.DataFrame()
imp_df["feature"] = list(train_features)
imp_df["importance_gain"] = clf.feature_importance(importance_type=`gain`)
imp_df["importance_split"] = clf.feature_importance(importance_type=`split`)
imp_df[`trn_score`] = roc_auc_score(y, clf.predict(data[train_features]))
return imp_df벤치마크를 위한 변수중요도 생성
원래의 논문에서는 변수의 실제 중요도에 관해 이야기하지 않지만, 변수가 실제로 가지는 변수 중요도 값을 같이 이해해야 한다고 생각합니다.
# seed 값을 설정하여줍니다.
np.random.seed(123)
# 셔플을 하지 않음으로 실제 변수중요도를 얻습니다.
actual_imp_df = get_feature_importances(data=data, shuffle=False)
actual_imp_df.head()Null Importances 분포 만들기
null_imp_df = pd.DataFrame()
nb_runs = 80
import time
start = time.time()
dsp = ``
for i in range(nb_runs):
# 셔플을 통해 null importance를 얻습니다.
imp_df = get_feature_importances(data=data, shuffle=True)
imp_df[`run`] = i + 1
# 이전에 얻었던 null importance와 지금 얻은 null importance를 결합합니다.
null_imp_df = pd.concat([null_imp_df, imp_df], axis=0)
# 이전의 메세지를 지웁니다.
for l in range(len(dsp)):
print(`\b`, end=``, flush=True)
# 현재 실행단계 및 사용시간을 표시합니다.
spent = (time.time() - start) / 60
dsp = `Done with %4d of %4d (Spent %5.1f min)` % (i + 1, nb_runs, spent)
print(dsp, end=``, flush=True)null_imp_df.head()분포의 예시
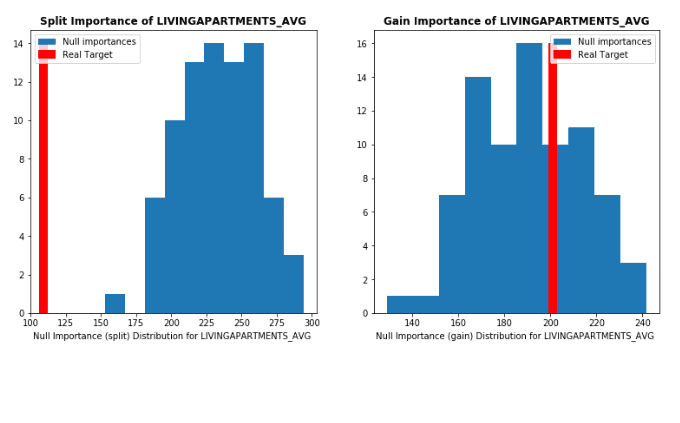
몇 개의 그림은 글보다 훨씬 이해하기 쉽습니다.
def display_distributions(actual_imp_df_, null_imp_df_, feature_):
plt.figure(figsize=(13, 6))
gs = gridspec.GridSpec(1, 2)
# Split importance를 그립니다.
ax = plt.subplot(gs[0, 0])
a = ax.hist(null_imp_df_.loc[null_imp_df_[`feature`] == feature_, `importance_split`].values, label=`Null importances`)
ax.vlines(x=actual_imp_df_.loc[actual_imp_df_[`feature`] == feature_, `importance_split`].mean(),
ymin=0, ymax=np.max(a[0]), color=`r`,linewidth=10, label=`Real Target`)
ax.legend()
ax.set_title(`Split Importance of %s` % feature_.upper(), fontweight=`bold`)
plt.xlabel(`Null Importance (split) Distribution for %s ` % feature_.upper())
# Gain importance를 그립니다.
ax = plt.subplot(gs[0, 1])
a = ax.hist(null_imp_df_.loc[null_imp_df_[`feature`] == feature_, `importance_gain`].values, label=`Null importances`)
ax.vlines(x=actual_imp_df_.loc[actual_imp_df_[`feature`] == feature_, `importance_gain`].mean(),
ymin=0, ymax=np.max(a[0]), color=`r`,linewidth=10, label=`Real Target`)
ax.legend()
ax.set_title(`Gain Importance of %s` % feature_.upper(), fontweight=`bold`)
plt.xlabel(`Null Importance (gain) Distribution for %s ` % feature_.upper())display_distributions(actual_imp_df_=actual_imp_df, null_imp_df_=null_imp_df, feature_=`LIVINGAPARTMENTS_AVG`)display_distributions(actual_imp_df_=actual_imp_df, null_imp_df_=null_imp_df, feature_=`CODE_GENDER`)display_distributions(actual_imp_df_=actual_imp_df, null_imp_df_=null_imp_df, feature_=`EXT_SOURCE_1`)display_distributions(actual_imp_df_=actual_imp_df, null_imp_df_=null_imp_df, feature_=`EXT_SOURCE_2`)display_distributions(actual_imp_df_=actual_imp_df, null_imp_df_=null_imp_df, feature_=`EXT_SOURCE_3`)위의 그림에서 Null Importance 방법의 장점이 보입니다. 특히 잘 알려진 사실은 다음과 같습니다.
- 충분한 차이가 있는 모든 기능을 트리 모델로 사용하고 이해할 수 있습니다. 더 나은 점수를 내는 데 도움이 되는 스플릿을 항상 찾을 수 있습니다.
- 상관 된 변수들은 변수 중 하나가 사용되면 다른 하나는 중요도가 감소하게 됩니다. 이렇게 선택된 변수는 매우 중요하며 관련 변수는 바뀐 중요도를 갖습니다.
현재 방법은 다음을 허용합니다.
- 목적변수와 실제로 관련이 없는 높은 분산을 가지는 변수들을 제거
- 상호 연관성이 있는 변수를 제거하여 실제 중요도 (또는 unbiased 중요도)을 보여줍니다.
점수 특징
변수를 평가하는 데는 여러 가지 방법이 있습니다.
- 실제 중요도와 Null importance 분포가 많이 떨어진 표본 수를 계산합니다.
- Actual / Null Max, Actual / Null Mean, Actual Mean / Null Max와 같은 비율을 계산합니다.
첫 번째 단계에서는 로그 실제 기능 중요도를 Null 분포의 75 백분위 수로 나눈 값을 사용합니다.
feature_scores = []
for _f in actual_imp_df[`feature`].unique():
f_null_imps_gain = null_imp_df.loc[null_imp_df[`feature`] == _f, `importance_gain`].values
f_act_imps_gain = actual_imp_df.loc[actual_imp_df[`feature`] == _f, `importance_gain`].mean()
gain_score = np.log(1e-10 + f_act_imps_gain / (1 + np.percentile(f_null_imps_gain, 75))) # Avoid didvide by zero
f_null_imps_split = null_imp_df.loc[null_imp_df[`feature`] == _f, `importance_split`].values
f_act_imps_split = actual_imp_df.loc[actual_imp_df[`feature`] == _f, `importance_split`].mean()
split_score = np.log(1e-10 + f_act_imps_split / (1 + np.percentile(f_null_imps_split, 75))) # Avoid didvide by zero
feature_scores.append((_f, split_score, gain_score))
scores_df = pd.DataFrame(feature_scores, columns=[`feature`, `split_score`, `gain_score`])
plt.figure(figsize=(16, 16))
gs = gridspec.GridSpec(1, 2)
# Split importance를 그립니다.
ax = plt.subplot(gs[0, 0])
sns.barplot(x=`split_score`, y=`feature`, data=scores_df.sort_values(`split_score`, ascending=False).iloc[0:70], ax=ax)
ax.set_title(`Feature scores wrt split importances`, fontweight=`bold`, fontsize=14)
# Gain importance를 그립니다.
ax = plt.subplot(gs[0, 1])
sns.barplot(x=`gain_score`, y=`feature`, data=scores_df.sort_values(`gain_score`, ascending=False).iloc[0:70], ax=ax)
ax.set_title(`Feature scores wrt gain importances`, fontweight=`bold`, fontsize=14)
plt.tight_layout()결과 데이터 저장
null_imp_df.to_csv(`null_importances_distribution_rf.csv`)
actual_imp_df.to_csv(`actual_importances_ditribution_rf.csv`)상관없는 기능 제거의 영향 확인
여기에서는 목적변수와의 상관관계를 측정하는 데 다른 측정 항목을 사용하겠습니다.
correlation_scores = []
for _f in actual_imp_df[`feature`].unique():
f_null_imps = null_imp_df.loc[null_imp_df[`feature`] == _f, `importance_gain`].values
f_act_imps = actual_imp_df.loc[actual_imp_df[`feature`] == _f, `importance_gain`].values
gain_score = 100 * (f_null_imps < np.percentile(f_act_imps, 25)).sum() / f_null_imps.size
f_null_imps = null_imp_df.loc[null_imp_df[`feature`] == _f, `importance_split`].values
f_act_imps = actual_imp_df.loc[actual_imp_df[`feature`] == _f, `importance_split`].values
split_score = 100 * (f_null_imps < np.percentile(f_act_imps, 25)).sum() / f_null_imps.size
correlation_scores.append((_f, split_score, gain_score))
corr_scores_df = pd.DataFrame(correlation_scores, columns=[`feature`, `split_score`, `gain_score`])
fig = plt.figure(figsize=(16, 16))
gs = gridspec.GridSpec(1, 2)
# Split importance를 그립니다.
ax = plt.subplot(gs[0, 0])
sns.barplot(x=`split_score`, y=`feature`, data=corr_scores_df.sort_values(`split_score`, ascending=False).iloc[0:70], ax=ax)
ax.set_title(`Feature scores wrt split importances`, fontweight=`bold`, fontsize=14)
# Gain importance를 그립니다.
ax = plt.subplot(gs[0, 1])
sns.barplot(x=`gain_score`, y=`feature`, data=corr_scores_df.sort_values(`gain_score`, ascending=False).iloc[0:70], ax=ax)
ax.set_title(`Feature scores wrt gain importances`, fontweight=`bold`, fontsize=14)
plt.tight_layout()
plt.suptitle("Features` split and gain scores", fontweight=`bold`, fontsize=16)
fig.subplots_adjust(top=0.93)다른 임계 값들에 따라 변수를 제거하고 점수 측정
def score_feature_selection(df=None, train_features=None, cat_feats=None, target=None):
# Lightgbm을 학습합니다.
dtrain = lgb.Dataset(df[train_features], target, free_raw_data=False, silent=True)
lgb_params = {
`objective`: `binary`,
`boosting_type`: `gbdt`,
`learning_rate`: .1,
`subsample`: 0.8,
`colsample_bytree`: 0.8,
`num_leaves`: 31,
`max_depth`: -1,
`seed`: 13,
`n_jobs`: 4,
`min_split_gain`: .00001,
`reg_alpha`: .00001,
`reg_lambda`: .00001,
`metric`: `auc`
}
# Lightgbm을 적용합니다.
hist = lgb.cv(
params=lgb_params,
train_set=dtrain,
num_boost_round=2000,
categorical_feature=cat_feats,
nfold=5,
stratified=True,
shuffle=True,
early_stopping_rounds=50,
verbose_eval=0,
seed=17
)
# 가장 최신의 평균과 표준편차를 반환합니다.
return hist[`auc-mean`][-1], hist[`auc-stdv`][-1]
for threshold in [0, 10, 20, 30 , 40, 50 ,60 , 70, 80 , 90, 95, 99]:
split_feats = [_f for _f, _score, _ in correlation_scores if _score >= threshold]
split_cat_feats = [_f for _f, _score, _ in correlation_scores if (_score >= threshold) & (_f in categorical_feats)]
gain_feats = [_f for _f, _, _score in correlation_scores if _score >= threshold]
gain_cat_feats = [_f for _f, _, _score in correlation_scores if (_score >= threshold) & (_f in categorical_feats)]
print(`Results for threshold %3d` % threshold)
split_results = score_feature_selection(df=data, train_features=split_feats, cat_feats=split_cat_feats, target=data[`TARGET`])
print(`\t SPLIT : %.6f +/- %.6f` % (split_results[0], split_results[1]))
gain_results = score_feature_selection(df=data, train_features=gain_feats, cat_feats=gain_cat_feats, target=data[`TARGET`])
print(`\t GAIN : %.6f +/- %.6f` % (gain_results[0], gain_results[1]))출처
Jupyter notebook 파일