
참고자료
-
원본 아티클 (Data Scientist’s Dilemma: The Cold Start Problem – Ten Machine Learning Examples Review)
- Data Scientist’s Dilemma
- 원본 아티클 저자 Kirk D. Borne는 Booz Allen Hamilton의 수석 데이터 과학자이자 수석 고문
들어가기 전에
-
기계학습
- Gradiet Descent : 함수의 최소값 위치를 찾는 문제에서 오차 함수의 그레디언트(gradient) 반대 방향으로 조금씩 움직여 가며 최적의 파라미터를 찾으려는 방법, 그레디언트는 각 파라미터에 대해 편미분한 벡터
- hill climbing : 언덕 오르기 방법, DFS(depth-first search)를 기초로 하여 local/heuristic을 적용한 탐색 기법으로 현재 상태와 자식 노드와의 거리(혹은 비용)에 따라 정렬(sort)한 후 각 단계(step)의 선택이 이전 단계의 상태보다 나은지를 평가함
- DFS : 깊이 우선 탐색, 초기 노드에서 시작하여 깊이 방향으로 탐색, 목표 노드에 도달하면 종료, 더 이상 진행할 수 없으면, 백트랙킹(backtracking, 되짚어가기), 방문한 노드는 재방문하지 않음
1. INTRODUCTION
- 기계학습의 알고리즘과 기법이 최적의 솔루션을 향해 모델을 학습하는 과정에서 좋은 판단을 내리도록 데이터 과학에서는 콜드 스타트 문제를 해결하는 일련의 사례를 제시합니다.
-
고대 철학자 공자는 “당신의 과거를 연구하여 당신의 미래를 알게 한다고” 말했습니다. 지혜는 삶 뿐만 아니라 기계학습에도 적용됩니다.
- 특히 과거에 보이지 않는 데이터(미래의 것)에 라벨(답지)을 붙이기 위한 라벨 데이터(과거 데이터)의 가용성 및 적용은 지도학습의 기본입니다.
- 과거 데이터에 레이블(진단, 클래스, 알려진 결과)이 없으면 데이터를 라벨링(설명)하는 과정을 어떻게 진행합니까?
-
콜드 스타트 문제는 비지도 기계학습에서도 발생할 수 있습니다. 콜드 스타트는 레이블이 지정된 훈련 데이터의 존재에 대한 요구 사항이나 추정은 없습니다.
- 데이터의 패턴 (예 : 추세, 상관 관계, 세그먼트, 클러스터, 연결)을 본질적으로 매개변수화 하거나 특성화
-
많은 비지도 학습 모델은 어떤 파라미터가 가장 잘 선택되는지 미리 알면 보다 쉽게 수렴하고 더 가치가 있을 수 있습니다.
- 즉, 비지도 학습이기때문에 알 수 없다면, 적어도 최종 모델이 (어떤 방식으로) 데이터를 설명하는데 최적이라는 것을 알고 싶을 수 있음
- 두 가지 애플리케이션 (지도 및 비지도 학습)에서 초기 통찰 및 유효성 측정 기준이 없는 경우 모델 구축이 어떻게 시작되어 최적의 솔루션으로 이동합니까?
2. Cold Start Problem
- 문제에 대한 해결책은 쉬운데 임의의 초기 추측(랜덤 무작위 값)을 통해서 해결합니다.
-
랜덤 무작위 값이 좋은 초기 추측인지 어떻게 알 수 있습니까?
- 무작위 초기 선택으로부터 모델의 파라미터를 어떻게 학습하고 정확한 모델로 옮겨가고 있음을 어떻게 알 수 있습니까?
-
물론 누구도 “콜드 스타트 (cold start)” 문제는 쉽지 않습니다
- 이른 아침에 얼어붙은 차가운 차를 운전하려고 시도해본 사람이라면 누구든지 추위에 시달리는 고통을 알 수 있습니다.
- 이른 아침에 다른 어떤 것도 더 좌절 할 수는 없습니다. 그러나 엔진이 시동을 걸고 차가 나아감에 따라 앞으로 나아가기 시작하는 그 순간보다 이른 아침에 더 기분을 고양시킬 수 있는 것은 없습니다.
- 기계학습에서 콜드 스타트 문제에 직면한 데이터 과학자를 위한 경험, 특히 모델이 성능이 향상됨에 따라 앞으로 나아갈 때 흥분감이 생길 수 있습니다.
-
마지막에는 몇 가지 예를 제시 할 것입니다.
- 그러나 시도하기 전에, Objective Funciton(목적 함수)를 다루겠습니다. 목적 함수는 콜드 스타트 문제에서 성능을 열어주는 진정한 열쇠입니다.
3. Objective Fuctnion
-
목적 함수(비용 함수 또는 이익 함수라고도 함)는 모델 성능의 객관적인 척도를 제공합니다.
- 모델이 올바르게 분류한 클래스 레이블의 백분율 (분류 모델) 또는 모델 곡선 (회귀 모델)의 편차 제곱의 합 또는 클러스터링 알고리즘에서는 클러스터들이 서로 분리가 잘 되고 간결하게 묶여있는지 판단합니다.
-
목적 함수의 값은 최종 값일뿐만 아니라 (즉, 정량적인 전체 모델 성능 등급을 제공), 초기 무작위 모델을 (희망적으로) 최적 모델로 변환합니다.
- 중간 단계에서는 평가 (또는 유효성 검사) 척도로 사용됩니다.
-
0단계 (콜드 스타트)에서 평가 척도를 측정하고 모델 매개변수를 조정한 후 다시 측정함으로써 조정 결과가 더 나은 수행 모델인지 또는 더 나쁜 성능인지를 알 수 있음
- 동일한 방향 또는 반대 방향으로 모델 매개변수 조정을 계속할지 여부를 알 수 있습니다. 그라디언트 디센트 통해서
-
기울기 하강 방법은 기본적으로 하나의 모델에서 다음 모델로 진행함에 따라 성능오차 곡선의 기울기 (즉, 그래디언트)를 찾음
- 초등학교 수학 수업에서 배운 것처럼 곡선의 기울기를 찾으려면 두 점이 필요합니다, 따라서 두 가지 모델을 실행하고 평가한 후, 성능 포인트를 갖게 됩니다.
- 즉, 최신 포인트의 곡선 기울기가 모델 매개변수 조정의 다음 선택 사항을 알려줍니다. (a) 동일한 방향으로 계속 조정합니다.
- 이전 단계 (성능 에러가 감소한 경우)로 에러 곡선 하강을 계속합니다. 또는 (b) 반대 방향으로 조정 (성능 오류가 증가한 경우) 합니다.
-
힐 클라이밍은 그래디언트 디센트와 반대이지만 본질적으로 똑같음
- 오차를 최소화하는 대신 (비용 함수), 힐 클라이밍은 정확도 극대화에 초점을 맞춥니다 (이익 함수)
- 다시 두 모델에서 성능 곡선의 기울기를 측정한 다음 성능이 우수한 모델의 방향으로 진행합니다. 두 가지 경우 (힐 클라이밍 및 그래디언트 디센트)에서 최적의 지점(최대 정확도 또는 최소 오차)에 도달하기를 희망하고 결과를 최적의 솔루션으로 찾음
-
기계학습 모델이 많은 매개변수(깊은 신경망의 경우 수천 개가 될 수 있음)를 가질 때, 계산은 더 복잡합니다 (아마도 텐서로 알려진 다차원 그라디언트 계산을 포함하여)
- 딥러닝도 원리는 동일, 모델 구축 진행의 각 단계에서 양적으로 발견하여 목표 매개변수의 최적 값으로 진행하기 위해 모델 매개변수 각각에 조정(크기 및 방향)이 필요함 (예 : 정확도 극대화, 적합성 최대화, 정밀도 극대화, 위양성 최소화 등)을 제공
- 딥러닝에서, 전형적인 신경망 모델들에서와 같이, 모델 파라미터들에 대한 조정들이 (즉, 네트워크 노드들간의 각각의 에지 가중치에 대해) 추정되는 방법은 역전파 (backpropagation)로 불림. 여전히 그래디언트 디센트를 기반으로 함
-
그라디언트 디센트, 역전파 및 모든 기계학습에 대해 생각하는 한 가지 방법은 다음과 같음
- 기계학습은 경험을 통해 학습하는 수학적 알고리즘 세트. 좋은 판단은 경험이 됩니다.
- 무작위 콜드 스타트 모델에 대한 초기 추측은 “나쁜 판단” 으로 간주될 수 있지만 경험 (즉, 그래디언트 디센트와 같은 유효성 측정 기준으로부터의 피드백)은 “좋은 판단”(더 나은 모델)을 모델 구축 워크플로우에 적용할 수 있음
4. Example
-
[1] 초기 클러스터 수단과 클러스터 수가 사전에 알려지지 않았기 때문에 임의로 선택되는 클러스터링 알고리즘 (예 : K-Means Clustering)은 클러스터의 간결성을 평가, 반복 및 평가하는 데 사용할 수 있습니다.
- 클러스터의 최종 집합 (즉, 가장 작고 잘 분리 된 클러스터)으로 진행되는 클러스터 집합을 향상시킴 (Ex. Silhouette Distance)
-
[2] 네트워크 에지의 초기 가중치가 임의로 (콜드 스타트) 할당되지만, 역전파 (backpropagation)는 모델을 최적의 네트워크 (가장 높은 분류 성능)로 반복하는 데 사용
-
[3] TensorFlow은 단순한 신경 네트워크와 동일한 역전파 기법을 사용하지만 Calculation of the weight Adjustments은 딥 네트워크 레이어의 매우 고차원적인 매개변수 공간과 텐서를 사용하는 에지 가중치를 통해 이루어짐
- Reverse-mode autodiff (HandsOnMachineLearningwithScikitLearnandTensorFlow 책 참고할 것)
-
[4] 최적 곡선을 찾기 위해 모델 곡선에서 편차 제곱의 합을 사용하는 회귀. 선형회귀 분석에서, 선형 최소 제곱합에서 유도할 수 있는 Closed 형태의 솔루션이 있음
- 비선형 회귀에 대한 솔루션은 일반적으로 Closed 형태의 수학 방정식 집합이 아니지만 편차 제곱의 합을 최소화하는 것은 계속 적용됨
- 최적의 곡선을 찾기 위해 반복 워크플로에서 그래디언트 디센트를 사용할 수 있음. K-Means Clustering은 실제로 piecewise regression의 예
-
[5] 그라디언트 디센트와 힐 클라이밍이 일반적으로 전역 최적 값이 아닌 로컬 최적 값에만 수렴하도록 목표함수에 많은 언덕과 계곡이 있는 genetic algorithms, particle swarm optimization (그라디언트를 계산할 수 없는 경우), evolutionary computing 방법을 사용하여 많은 무작위 (콜드 스타트) 모델을 생성 한 다음 전역 최적을 찾을 때까지 각각을 반복
- 시간과 자원이 부족한 다음 찾을 수 있는 최상의 것을 선택하십시오. 유전 알고리즘에 대한 샘플 유스 케이스를 보여주는 아래 첨부 된 그래픽을 참조
- 유전자 알고리즘은 기계학습 알고리즘이 아니며 실제로는 메타 학습 알고리즘
-
[6] kNN (k-Nearest Neighbors)는 데이터 집합 자체가 모델이 되는 지도학습 기법
- 즉, 새로운 데이터 포인트를 특정 그룹 (클래스 레이블 또는 특정 의미를 가질 수도 있고 가지지 않을 수도 있음)에 할당하는 것은 기존 데이터 포인트의 어떤 카테고리(그룹)가 대다수인지를 단순히 발견할 때 가장 가까운 이웃들의 투표를 새로운 데이터 포인트로 가져가는 것
- 검사 될 가장 가까운 이웃의 수는 임의의 수 k이며, 초기에는 임의적 일 수 있지만 (콜드 스타트), 모델 성능을 향상시키기 위해 조정됨

-
[7] Naive Bayes 분류는 베이지 정리를 데이터 항목에 클래스 라벨이 있는 대용량 데이터 세트에 적용하지만 속성 및 기능의 일부 조합은 훈련 데이터에 표시되지 않음
- 상이한 속성들이 데이터 아이템의 상호 독립적인 특징이라고 가정함으로써, 훈련 데이터에서 발견되지 않는 특징 벡터 (속성들의 세트)를 갖는 새로운 데이터 아이템에 대한 클래스 라벨이 무엇인지에 대한 posterior likelihood를 추정 할 수 있음
- 때로 Bayes Belief Network (BBN)라고도 하며 데이터 세트가 모델이 되는 또 다른 예. 여러 속성의 발생 빈도가 속성의 여러 조합의 예상 발생 빈도를 개별적으로 알릴 수 있음
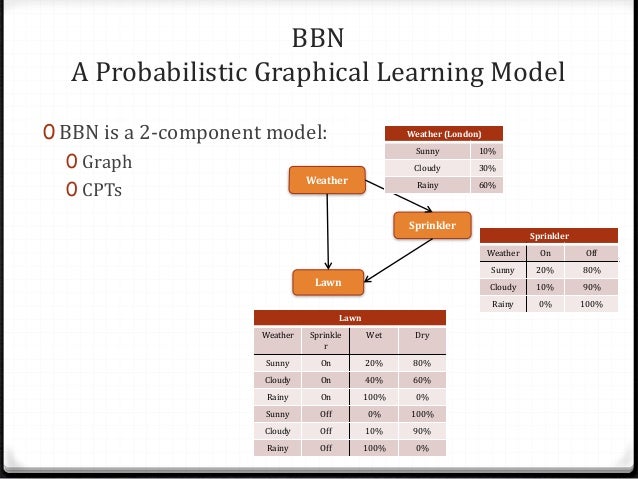
- [8] 마르코프 모델링 (시퀀스에 대한 Belief Networks)은 웹로그, 구매 패턴, 유전자 시퀀스, 음성 샘플, 비디오, 주가 또는 기타 시간적 또는 공간적 또는 매개변수 순서를 포함 할 수 있는 시퀀스에 BBN을 확장 한 것입니다.
-
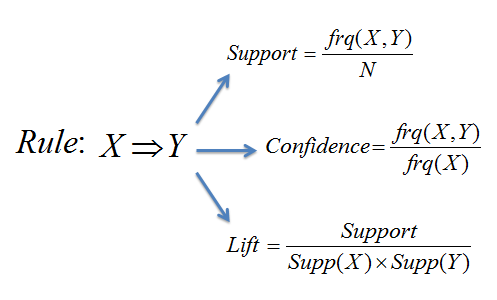
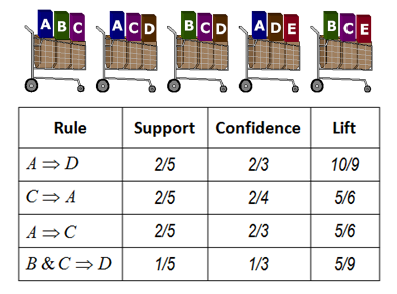
[9] 연관규칙 마이닝 : 데이터 세트의 무작위 샘플링에서 예상보다 높은 동시 발생 연관을 검색
- 연관 규칙 마이닝은 데이터 세트가 모델이 되는 또 다른 예이며, 연관되어 있는 사전 지식이 알려져 있지 않음 (즉, 콜드 스타트 챌린지)
- 기법은 Market Basket Analysis라고도 하며 간단한 콜드 스타트 고객구매 권장 사항에 사용되었지만 열대성 태풍 (허리케인) 강화 예측과 같은 이국적인 사용 사례에서도 사용되었음
-
[10]네트워크의 패턴 (e.g., centrality, reach, degrees of separation, density, cliques, etc.)
- 네트워크 (e.g.,most authoritative or influential nodes in the network) 지식을 인코딩하는 소셜 네트워크 (링크) 분석 패턴 (예 : 콜드 스타트)에 대한 사전 지식없이 PageRank와 같은 알고리즘을 적용
-
참고하면 좋은 아티클
- The Cold Start Problem for Recommender Systems (추천 시스템의 콜드 스타트 문제)
- Tackling the Cold Start Problem in Recommender Systems (추천 시스템의 콜드 스타트 문제 해결)
- Approaching the Cold Start Problem in Recommender Systems (추천 시스템에서 콜드 스타트 문제에 접근하기)

-
참고 : Genetic Algorithms (GA)는 메타 학습의 한 예
- 기계학습 알고리즘 자체는 아니지만, 지역 최적 솔루션 모음에서 최적의 모델 (아마도 글로벌 최적인 모델)을 찾기 위해 기계학습 모델 및 작업의 앙상블에 걸쳐 GA를 적용할 수 있음