들어가며
이 포스트는 원문의 저자인 Sebastian Ruder 가 2018년 자연어 처리 분야의 흥미롭고 중요한 10 가지 아이디어에 대해 선정하고 정리한 글을 번역하였습니다. 저자는 앞으로 이 아이디어들을 더 자주보게 될 것이라고 합니다.
또한, 각각의 아이디어들에 대해서 직접 선정한 1 ~ 2 개의 관련된 주요 논문을 소개했으며, 본 포스트에서는 원문 포스트의 `My Highlight` 를 `[Ruder's Highlight]` 로 표기했습니다.
저자는 논문들의 리스트를 최대한 간결하게 유지하려고 했기 때문에, 다루지 못한 관련 작업들이 있음에 대해서 사전에 양해를 구하며 주로 전이학습(Transfer Learning) 과 일반화(Generalization) 와 관련된 아이디어를 많이 다루었다고 언급했습니다. 이들 중 현재 트렌드가 아닌 것도 있지만 2019년에 더 트렌디 해질 것으로 기대되는 것도 있다고 합니다.
Sebastian Ruder 의 블로그는 자연어 처리 분야의 다양한 문제들에 대해서 소개하고 요약된 정보를 제공해주는 블로그로 자연어 처리 분야에 관심이 있는 분들께서는 자주 살펴보시기를 적극 추천 드립니다!
원문 링크 : http://ruder.io/10-exciting-ideas-of-2018-in-nlp/
1. Unsupervised MT
(비지도 기계 번역) ICLR 2018 컨퍼런스에서 비지도학습 기반의 기계번역을 주제로 한 논문이 2개 있었습니다. 이 논문들에서 제안한 비지도학습 기반의 기계번역 모델은 꽤 잘 작동한다는 점에서 놀라웠지만, 여전히 지도학습 기반의 기계 번역보다는 성능이 낮았습니다. 이후 EMNLP 2018 에서 앞의 두 그룹들이 그들의 이전 방법들을 상당히 발전시킴으로써 비지도 기계번역의 수준은 전보다 한 걸음 더 나아가게 되었습니다.
[Ruder’s Highlight]
Phrase-Based & Neural Unsupervised Machine Translation (EMNLP 2018) :
이 논문은 비지도 학습 기반 기계번역에서 필요한 세 가지 핵심 요소 에서 distilling(불필요한 것을 걷어내고 핵심만 추출) 을 하는 멋진 연구를 선보였습니다. 이 세가지 핵심 요소들은 이후 보게 될 다른 비지도 학습 시나리오에 대해서도 도움이 될 것입니다. 역번역을 모델링하는 것은 순환적인 일치성(cyclical consistency) 을 강제합니다. 이 순환적인 일치성은 대표적으로 CycleGAN 과 같은 다른 분야들에서 사용되어 오던 것입니다. 해당 논문은 광범위한 실험들을 수행했으며, 심지어 언어쌍 데이터가 많이 없는 영어-우르드어와 영어-루마니아어에 대한 평가도 진행했습니다. 미래에는 언어쌍 데이터가 많이 없는 언어들에 대해서도 더 많은 연구들을 볼 수 있을 것으로 기대됩니다.
비지도 기계번역의 세 가지 핵심 요소
- 좋은 시작점 찾기 (Good Initialization)
- 언어 모델링 (Language Modeling)
- 역번역 (Back-Translation)
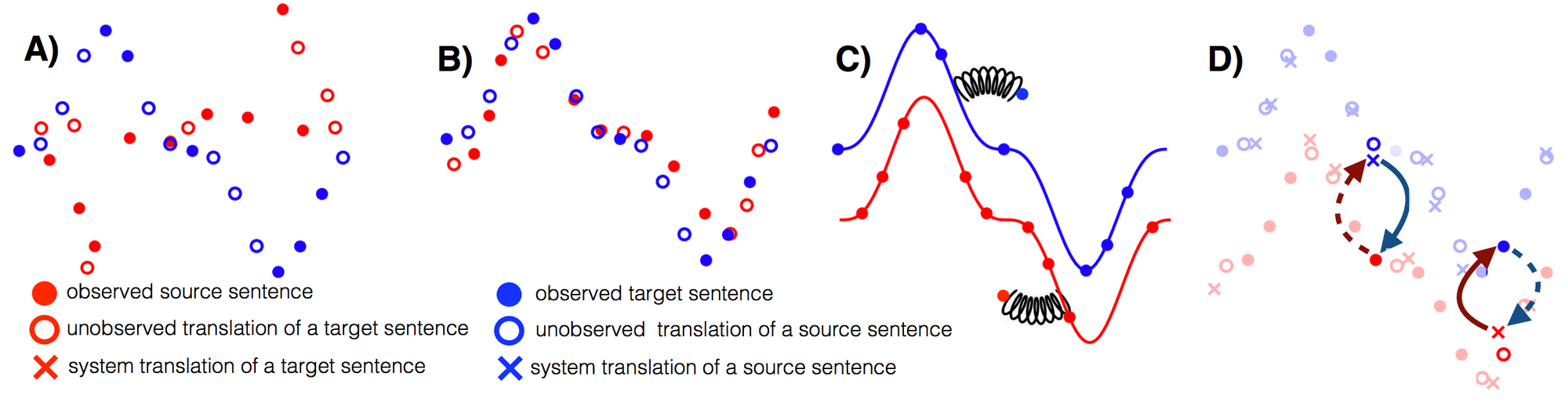
Toy illustration of the three principles of unsupervised MT. A) Two monolingual datasets. B) Initialization. C) Language modelling. D) Back-translation (Lample et al., 2018).
2. Pretrained language models
(사전 학습된 언어 모델들) 사전 학습된 언어 모델들의 사용은 아마도 2018년의 가장 중요한 NLP 트렌드일 것입니다. 그래서 저는 이 부분을 설명하는 것에 너무 많은 시간을 쓰지는 않으려고 합니다. ELMo, ULMFiT, OpenAI Transformer, BERT 등 많은 기억에 남을 만한 접근들이 있었습니다.
[Ruder’s Highlight]
Deep contextualized word representations (NAACL-HLT 2018) :
ELMo 를 소개한 이 논문은 많은 찬사를 받아 왔습니다. 인상깊은 실험 결과 외에도, 이 논문이 빛을 발하는 이유는 다양한 요인(factor)들이 미치는 영향력과 표상들(representations)에서 포착된 정보를 알려주는 세심한 분석 때문입니다. 아래 그림의 왼쪽에 해당하는 어의 중의성 해소(Word Sense Disambiguation, WSD)에 관해 스스로 진행한 평가는 잘 수행 되었습니다. 어휘 중의성 해소와 형태소 분석 두가지 분야에 대해 논문에서 제시한 언어 모델은 최고 성능에 근접했음을 보여줍니다.
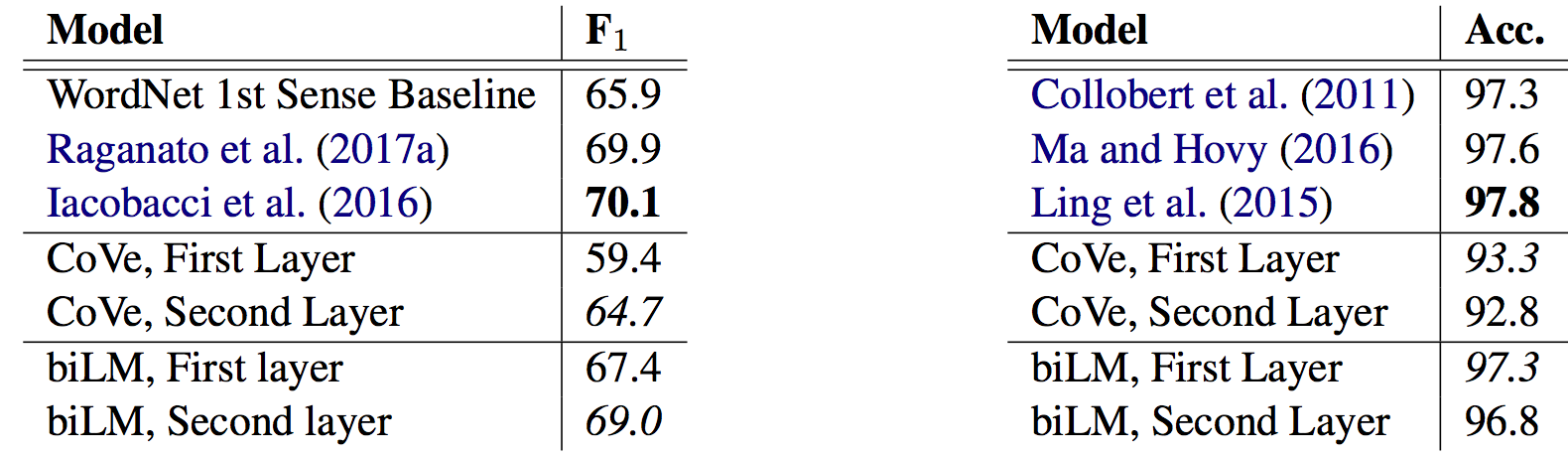
Word sense disambiguation (left) and POS tagging (right) results of first and second layer bidirectional language model compared to baselines (Peters et al., 2018).
3. Common sense inference datasets
(상식 추론 데이터셋) 일반 상식을 우리의 모델에 통합하는 것은 앞으로 나아가야 할 가장 중요한 방향 중 하나일 것입니다. 하지만, 좋은 데이터셋을 생성하는 것은 쉽지 않으며 심지어 유명한 데이터셋들도 큰 편향(bias) 을 보여줍니다. 2018년엔 모델에 몇몇 상식들에 대해서 가르치기 위해 잘 만들어진 데이터셋들이 공개되었습니다. 워싱턴 대학교에서 만든 Event2Mind 와 SWAG 이 그 예입니다. 이 중 SWAG 데이터셋은 매우 빠르게 해결되기도 했습니다.
[Ruder’s Highlight]
Visual Commonsense Reasoning(arXiv 2018) :
이 데이터셋은 각각의 답변에 합리적인 설명을 포함한 첫 Visual QA 데이터셋입니다. 또한, 질문들은 복잡한 추론을 요구합니다. 제작자들은 가능한 모든 편향(bias) 을 조절하기 위해 많은 노력을 했습니다. 이를 위한 구체적인 방법으로 모든 답변들이 전체 데이터셋에서 3번은 오답, 1번은 정답으로 나타나도록 하여 총 4번만 포함되도록 조정함으로써 모든 답변들의 사전 확률이 정확히 25% 가 될 수 있게 하였습니다. 이러한 구성은 관련성과 유사성을 계산하는 모델을 사용해 제한된 최적화 문제를 풀어야 가능합니다. 앞으로 가능한 모든 편향을 방지하는 것은 데이터셋을 구축하는 과정에서의 일반적인 구성요소가 될 것 입니다. 아래쪽, 이 데이터셋에 대한 굉장한 프레젠테이션을 한번 보시기 바랍니다!
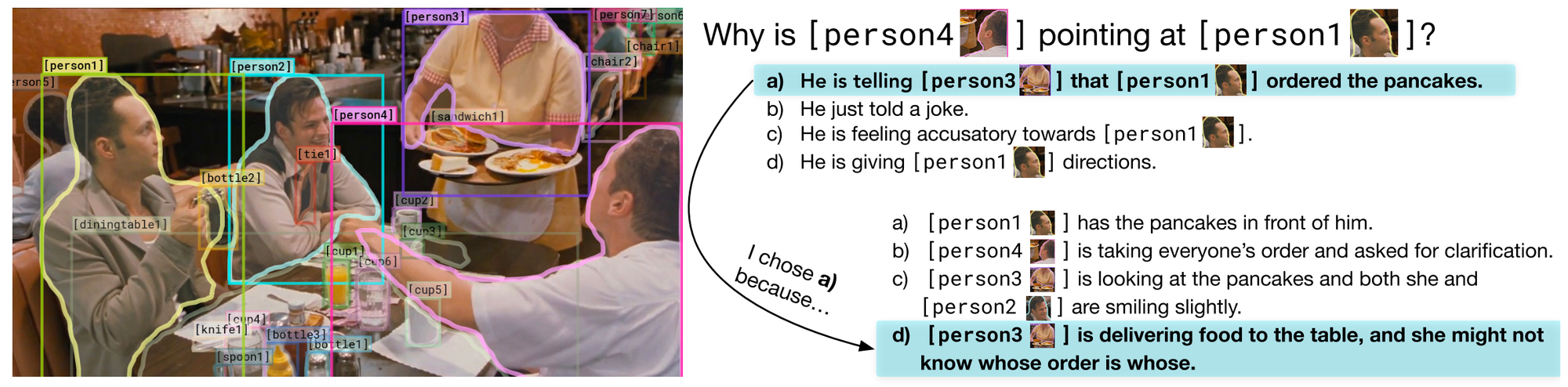
VCR: Given an image, a list of regions, and a question, a model must answer the question and provide a rationale explaining why its answer is right (Zellers et al., 2018).
4. Meta-Learning
(메타 러닝) 메타 러닝(Meta-learning) 은 그동안 few-shot learning 과 강화학습 그리고 로봇공학 분야에서 많이 사용되어 왔습니다 - 가장 유명한 사례 : model-agnostic meta-learning(MAML) - 그러나 자연어 처리 분야에서의 성공적인 적용사례는 매우 희귀했습니다. 메타 러닝은 제한된 숫자의 학습 데이터만 존재하는 문제들을 해결하는데 가장 유용한 방법입니다.
[Ruder’s Highlight]
Meta-Learning for Low-Resource Neural Machine Translation (EMNLP 2018) :
저자들은 번역에서의 좋은 시작점을 찾기 위해 각각의 언어쌍을 독립적인 메타 문제로 분리하여 정의한 후 MAML 을 사용했습니다. 학습 데이터셋이 적은 언어들에 적응하는 것은 메타 러닝을 자연어 처리에 적용하는데 아마도 가장 유용한 방법일 것입니다. 특히, 다언어 전이학습(multilingual transfer learning), 비지도 학습과 메타 러닝을 결합하는 것은 앞으로 매우 유망합니다.
The difference between transfer learning multilingual transfer learning, and meta-learning. Solid lines: learning of the initialization. Dashed lines: Path of fine-tuning (Gu et al., 2018).
5. Robust unsupervised methods
(강건한 비지도 방법들) 2018년, 우리는 비지도 학습 기반의 언어간 단어 임베딩 방법이 언어 간 상이함이 클 때 무너지는 것을 목격했습니다. 이는 모델의 성능 저하를 일으킬 수 있는 소스와 타겟이 불일치 하는 환경에서 전이 학습을 할 때 발생하는 흔한 현상입니다 (e.g. domain adaptation, continual learning, multi task learning). 모델을 이런 변화들에 대해 강건하게 하는 것은 따라서 매우 중요한 일입니다.
[Ruder’s Highlight]
A robust self-learning methods for fully unsupervised cross-lingual mappings of word embeddings (ACL 2018) :
이 논문은 시작점을 찾는것에 대한 메타 러닝 대신에 문제에 대한 그들의 이해를 바탕으로 보다 나은 시작점 찾기를 시도합니다. 특히, 이 논문의 저자들은 비슷한 단어들의 분포를 가진 두 개의 언어에 대해 단어들을 쌍(pair)으로 만들었습니다. 이는 도메인 전문 지식과 분석 통찰력을 사용해 모델을 보다 강력하게 만드는 훌륭한 예시입니다.
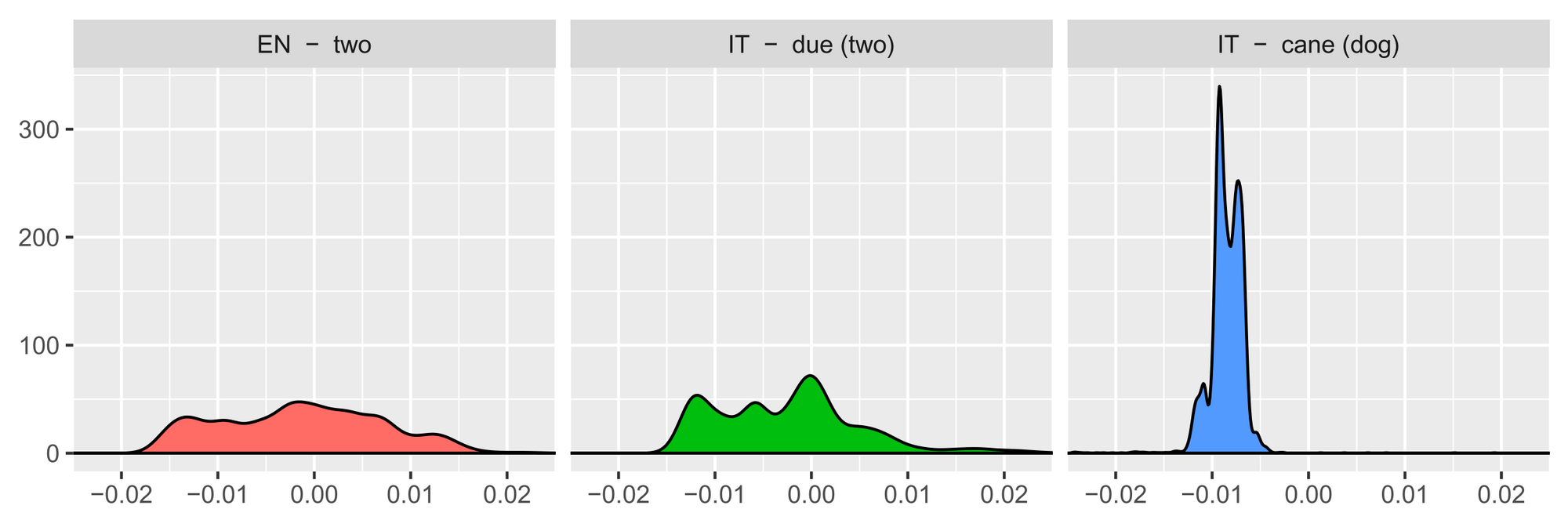
The similarity distributions of three words. Equivalent translations (‘two’ and ‘due’) have more similar distributions than non-related words (‘two’ and ‘cane’—meaning ‘dog’; Artexte et al., 2018).
6. Understanding representations
(표상에 대한 이해) 그동안 표상(representation) 들을 더 잘 이해하기 위한 많은 시도들이 있어왔습니다. 특히, ___진단 분류기___ (diagnostic classifiers) 는 꽤 흔해졌습니다.
diagnostic classifiers : 학습된 표상이 특적 속성을 예측할 수 있는지에 대한 측정을 목표로 하는 작업
[Ruder’s Highlight]
Dissecting Contextual Word Embeddings : Architecture and Representation (EMNLP 2018) :
이 논문은 사전 학습된 언어 모델 표상들에 대한 더 나은 이해에 대한 훌륭한 연구를 수행했습니다. 그들은 사전 학습된 단어와 스팬(span)에 대한 표상들에 대해 세심하게 설계된 비지도, 지도학습 문제들에 대해 광범위하게 연구 했습니다. 연구의 결과는 다음과 같습니다. 사전 학습된 표상들은 저수준의 형태학적 구문학적 특성에 대해서 낮은 단계의 레이어에서 학습하게 되며 긴 범위의 의미들은 높은 단계의 레이어 층에서 학습하게 된다는 것입니다. 이 사실은 마치 이미지넷(ImageNet) 데이터 셋을 통해 사전 학습된 컴퓨터 비전 분야의 모델들과 유사하게 특징을 포착하는 것을 보여주었습니다.
Per-layer performance of BiLSTM and Transformer pretrained representations on (from left to right) POS tagging, constituency parsing, and unsupervised coreference resolution (Peters et al., 2018).
7. Clever auxiliary tasks
(영리한 보조 작업들) 우리는 멀티태스크(multi-task) 학습이 신중하게 선택된 보조 작업들과 함께 사용되는 것이 증가하는 것을 많은 부분에서 볼 수 있었습니다. 좋은 보조 작업들을 위해, 데이터는 쉽게 접근가능해야 합니다. 가장 유명한 사례가 바로 BERT 입니다. BERT 는 Skip thoughts 및 최근 Quick thoughts 에서 사용되어져 오던 다음 문장 예측(next-sentence prediction) 을 사용해 큰 효과를 냅니다.
[Ruder’s Highlight]
Syntactic Scaffolds for Semantic Structures (EMNLP 2018) :
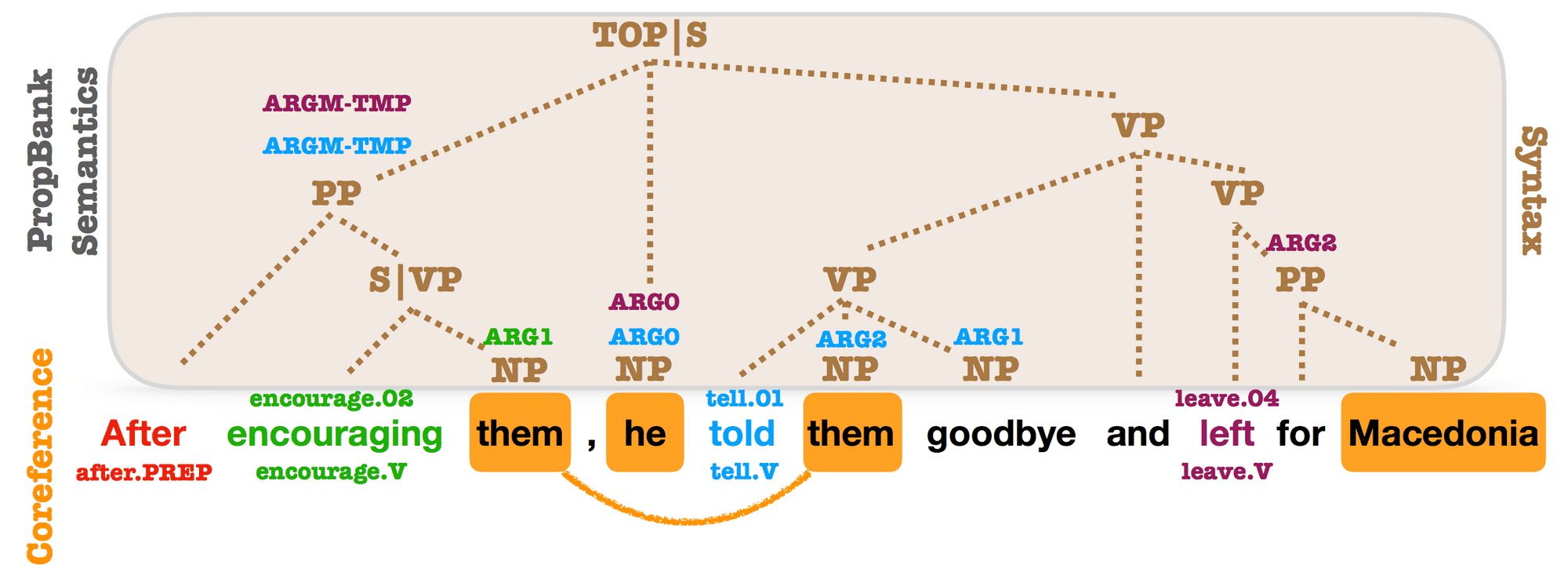
이 논문은 각 범위(span) 에 대해 대응하는 구문적인 구성요소 유형을 예측하는 것을 통해 스팬(span) 표상을 사전 학습시키는 보조 작업을 제안 했습니다. 컨셉적으로는 간단해 보이지만 이 보조 작업을 통해 의미역 결정(semantic role labeling)과 상호참조해결(coreference resolution) 분야에서 큰 성능 향상을 이끌었습니다. 이 논문은, 타겟 문제의(여기서는 스팬(span)) 필요에 의해 특화되어 학습된 표상이 굉장히 유익하다는 것을 보여주었습니다.
pair2vec : Compositional Word-Pair Embeddings for Cross-Sentence Inference (arXiv 2018) :
위와 비슷한 맥락에서, 이 논문은 단어 쌍 표상을 문맥 속에서 단어 쌍들의 점 상호 의존 정보(pointwise mutual information, PMI) 를 최대화 하는 것을 통해 사전에 학습시킵니다. 이는 모델이 언어 모델과 같은 일반적인 목적보다는 더 의미있는 단어 쌍들의 표상을 학습하는 것을 돕게 됩니다. 사전 학습된 표상들은 SQuAD 와 MultiNLI 와 같은 문장간 추론이 필요한 문제들에서 매우 효과적으로 작용합니다. 우리는 앞으로 특정 다운스트림 작업들에 특히 적합한 속성을 포착하면서, 언어 모델링과 같은 일반적인 목적의 작업을 보완 할 수 있는 사전 학습 작업들을 더 많이 보게 될 것으로 기대해 볼 수 있습니다.
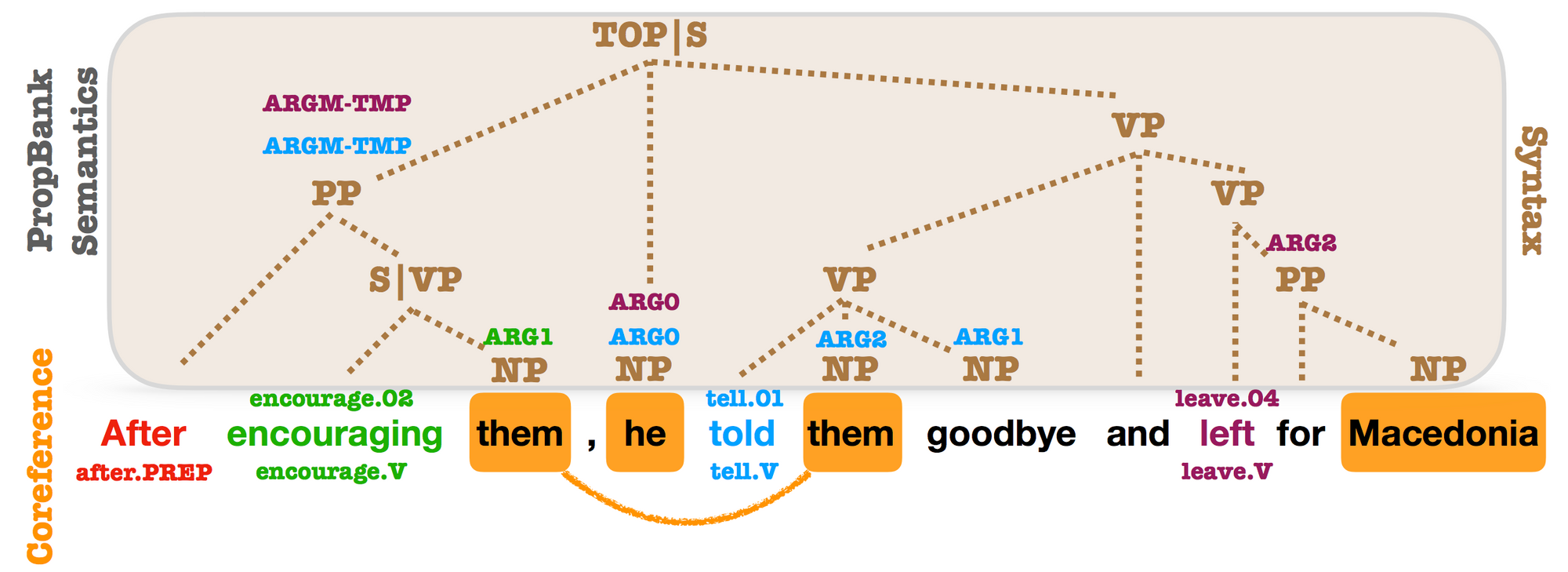
Syntactic, PropBank and coreference annotations from OntoNotes. PropBank SRL arguments and coreference mentions are annotated on top of syntactic constituents. Almost every argument is related to a syntactic constituent (Swayamdipta et al., 2018).
8. Combining semi-supervised learning with transfer learning
(준지도학습과 전이학습의 결합) 전이 학습에서의 최근의 발전함에 따라 우리는 타겟 문제에 특화된 데이터를 사용하는 명확한 방법을 사용하는 것을 잊어서는 안됩니다. 사실, 사전 학습된 표상은 준 지도학습의 여러 형태와 보완적입니다. 우리는 준 지도 학습의 특정 분야 중 하나인 셀프-라벨링(self-labeling) 접근에 대해서 그동안 연구해왔습니다.
[Ruder’s Highlight]
Semi-Supervised Sequence Modeling with Cross-View Training (EMNLP 2018) :
이 논문은 컨셉적으로 매우 간단한 아이디어를 보여줍니다. 바로, 입력에 대한 다른 관점으로의 예측들이 주 모델의 예측과 일치하는지 확인하는 것을 통해 다양한 작업들에서 이익을 얻을 수 있다는 것입니다. 이 아이디어는 단어-드롭아웃(word dropout) 과 유사하지만 라벨이 없는 데이터를 활용하여 모델을 더욱 강력하게 만들 수 있습니다. mean teacher 와 같은 다른 셀프-앙상블 모델들과 비교해 볼 때, 이 아이디어는 특정 자연어 처리 문제를 위해 특별히 설계되었습니다. 암묵적인 준 지도학습에 대한 많은 연구와 함께, 우리는 진보하고 있는 타겟에 대한 예측을 명시적으로 시도하는 더 많은 작업을 기대해 볼 수 있을 것입니다.
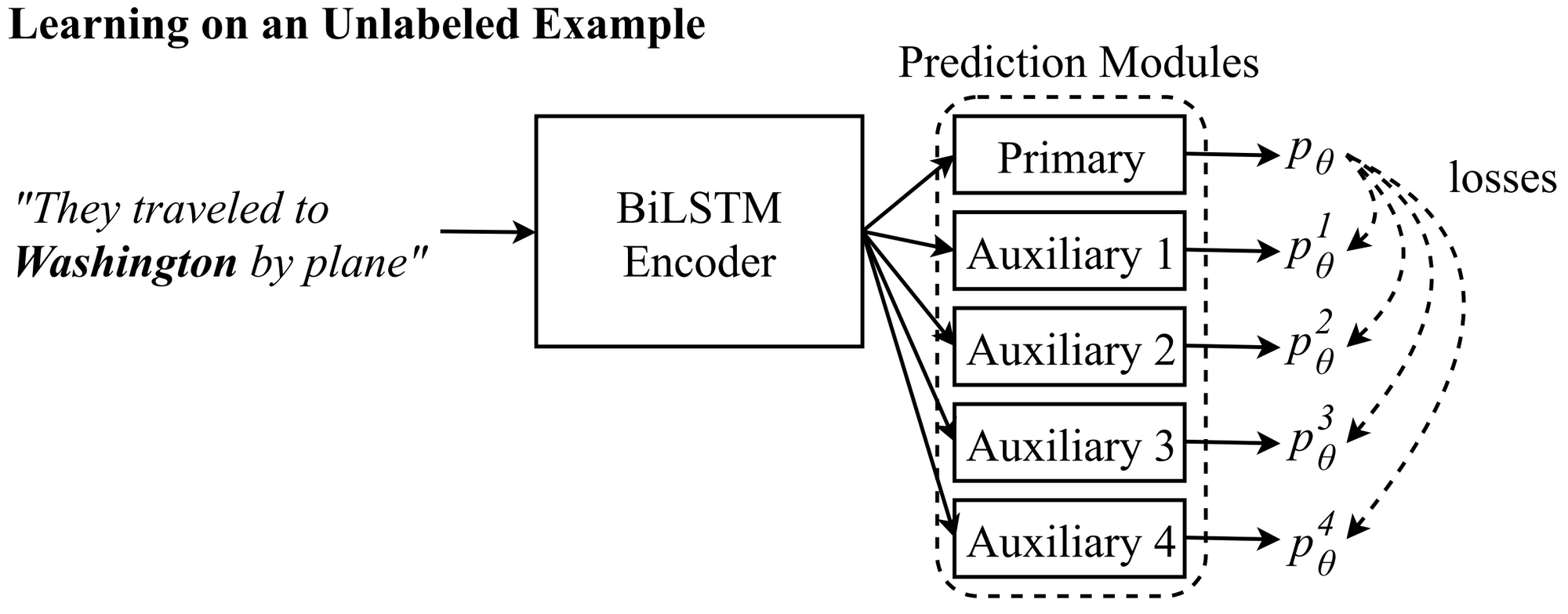
Inputs seen by auxiliary prediction modules (Clark et al., 2018):
Auxiliary 1: They traveled to __.
Auxiliary 2: They traveled to Washington ___.
Auxiliary 3: _ Washington by plane.
Auxiliary 4: ____ by plane.
9. QA and reasoning with large documents
(대용량 문서에 대한 질의응답 및 추론) 새로운 QA 데이터 셋들로 인해 질의 응답 분야에 대한 많은 발전이 이루어지고 있습니다. 대화형 QA 그리고 다단계 추론(multi-step reasoning) 뿐만 아니라, 질의 응답 분야에서 가장 어려운 부분 중 하나는 담화와 많은 양의 정보들을 통합하는 것입니다.
[Ruder’s Highlight]
The NarrativeQA Reading Comprehension Challenge (TACL 2018) :
이 논문은 전체 영화 대본과 책들에 대한 질문들을 답변해야하는 상당히 풀기 어려운 QA 데이터 셋을 새롭게 제안했습니다. 이 문제를 푸는 것은 현재 방법론들로는 아직까지 도달 할 수 없기 때문에, 전체 책 대신에 요약본을 사용 하거나 답변을 생성하는 것 대신 선택하기, 정보 검색 모델로 부터 추출된 결과물을 사용할 수 있는 옵션이 제공됩니다. 이러한 옵션을 사용하는 것을 통해 문제 해결을 보다 쉽게 수행할 수 있으며, 모델이 점진적으로 전체 설정(옵션을 사용하지 않는) 으로 확장해 나갈 수 있도록 할 수 있습니다. 우리에게는 이런 도전적이고 야심있는 문제들을 제시하면서도 언제든 접근 가능하도록 만드는 더 많은 데이터셋이 필요합니다.
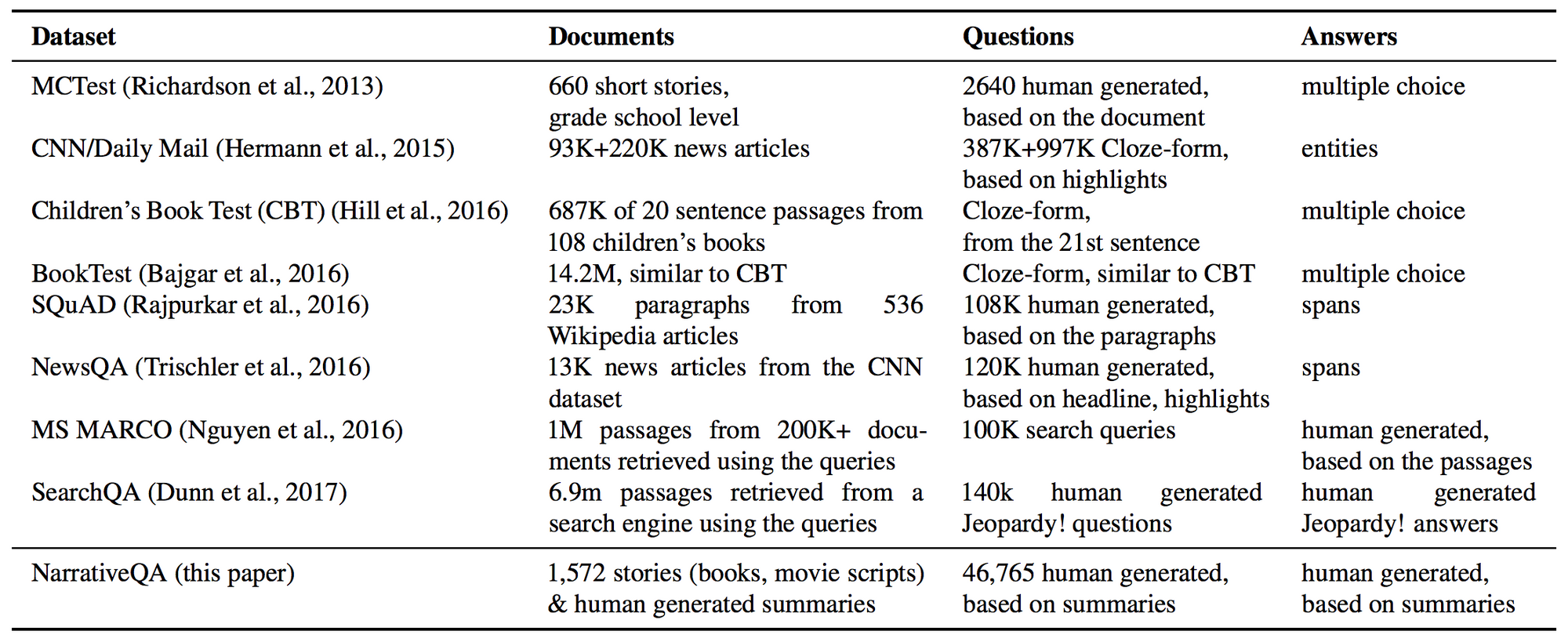
Comparison of QA datasets (Kočiský et al., 2018).
10. Inductive bias
(유도적인 편향) CNN 에서의 컨볼루션, 정규화(Regularization), 드롭아웃 그리고 다른 많은 메커니즘들과 같은 유도적인 편향들은 인공 신경망 모델에서 `regularizer` 로 동작하거나 모델을 더 표본-효율적(sample-efficient) 으로 만드는 핵심적인 부분입니다. 하지만, 광범위하게 유용한 유도적인 편향을 모델과 통합하는 것은 어려운 일입니다.
[Ruder’s Highlight]
Sequence classification with human attention(CoNLL 2018) :
이 논문은 RNN 을 이용한 학습에서 어텐션을 정규화 하기 위해 시선 추적 말뭉치들(eye-tracking corpora)을 통해 인간의 어텐션을 사용하는 것을 제안했습니다. 트랜스포머(Transformers) 와 같은 많은 현재의 모델들이 어텐션 메커니즘을 사용한다는 점에서, 더 효율적으로 훈련을 시킬 수 있는 방법을 찾는 것은 매우 중요한 방향입니다. 또한 인간의 언어 학습이 우리의 연산 모델의 성능을 향상시킬 수 있다는 또 다른 예를 찾아 보는 것도 매우 좋습니다.
Linguistically-Informed Self-Attention for Semantic Role Labeling (EMNLP 2018) :
이 논문은 좋은 점을 참 많이 가지고 있습니다.
- 구문적, 의미적 작업들을 동시에 학습시킨 트랜스포머
- 양질의 품사 해석을 테스트 단계에서 주입할 수 있는 능력
- 외부 영역(out-of-domain) 에 대한 평가
또한, 이 논문은 트랜스 포머의 헤드(head) 하나 하나를 개별 토큰의 구문적인 부모 노드에 집중하도록 훈련시키는 것을 통해 정규화하여 멀티헤드(multi-head) 어텐션을 더욱 구문에 대해 민감하게 반응하도록 했습니다. 우리는 앞으로 트랜스포머 어텐션 헤드(head) 들이 인풋의 특정 측면에 집중하는 보조적인 예측자로 사용되는 것을 더 많이 볼 수 있을 것입니다.

10 years of PropBank semantic role labeling. Comparison of Linguistically-Informed Self-Attention (LISA) with other methods on out-of-domain data (Strubell et al., 2018).