참고자료
-
원본 아티클
- The Illustrated Word2vec, 저자 Jay Alammar
1. INTRODUCTION
-
머신러닝에서 가장 매혹적인 아이디어 중 하나가 임베딩이라는 개념이라고 생각합니다.
-
다음 단어를 예측하는 Siri(시리), 구글 어시스턴트, 알렉사, 구글 번역기, 심지어 스마트폰 키보드는 자연어 처리 모델의 중심이 된 임베딩이 큰 힘이 되었을 것입니다.
-
지난 수십년 동안 신경망 모델에 임베딩을 사용하는데 상당한 발전이 있었습니다 (최근의 개발은 BERT 및 GPT2)와 같은 최첨단 모델로 이어지는 문맥적 단어 임베딩을 포함합니다.
-
Word2vec은 Word Embeddings을 효율적으로 만드는 방법이며 2013년에 나왔습니다.
- 그러나 Word Embeddings 방법으로서의 유용성 외에도 일부 개념은 추천시스템을 만들고 상업적, 비언어 작업에서도 순차적 데이터를 이해하는 데 효과적이라는 것이 입증되었음
- 에어비앤비, 알리바바, 스포티파이, 안가미 같은 회사들은 모두 NLP의 세계에서 머신러닝에서 새로운 종류의 추천 시스템을 개발할 수 있도록 활용함으로써 이익을 얻었음
-
이 글에서는 임베딩이라는 개념과 word2vec으로 임베딩을 생성하는 메커니즘을 살펴볼 것
- 어떤 것을 표현 하는 벡터를 예시로 얘기를 시작하고자 합니다
- 다섯 개의 숫자로 이뤄진 리스트(벡터)로 당신의 성격(MBTI)을 그렇게 많이 표현할 수 있다는 것을 알고 있었나요?
Personality Embeddings: What are you like?
- 0에서 100까지의 척도로 당신을 표현한다면, 얼마나 내향적이거나 외향적입니까 (0은 가장 내향적이며 100은 가장 외향적)?
- MBTI 같은 성격 테스트를 해본 적이 있는가, 아니면 더 나은 5대 성격 특성 테스트를 해본 적이 있는가?

-
- 내향성/ 외 향성 점수로 38/100을 기록했다고 상상해보자.
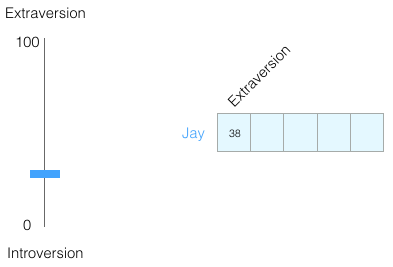
- 범위를 -1에서 1로 전환합시다.

-
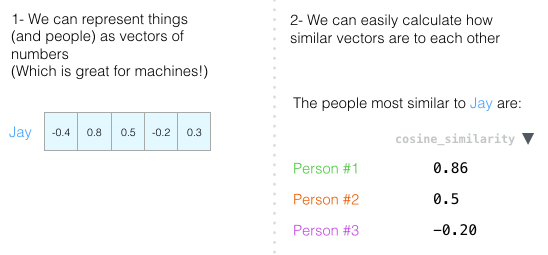
하나의 정보만 가지고 사람을 파악할 수 있을까?
- No, 사람들은 복잡하기 때문에 다른 차원을 추가해보자. 테스트에서 얻은 다른 특성의 점수
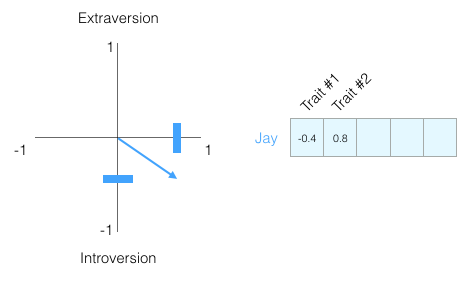
- 두 차원을 그래프의 한 점으로 표현할 수 있습니다. 또는 원점에서 그점까지의 벡터로 표현할 수 있습니다
- 사람의 성격을 벡터로 표현하는 데서 많은 가치를 얻습니다
-
벡터가 부분적으로 나의 성격을 나타낸다고 말할 수 있습니다
- 표현의 유용성은 다른 두 사람을 나와 비교하고 싶을때 나옵니다
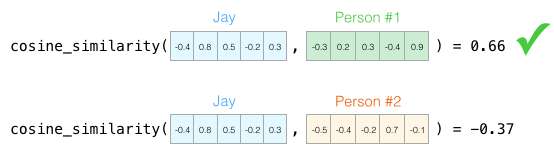
- 비슷한 성격의 사람이 나의 업무(버스 운전)를 대신하다고 했을 때 다음 그림에서 두 사람 중 어느 쪽이 나와 더 비슷할까?
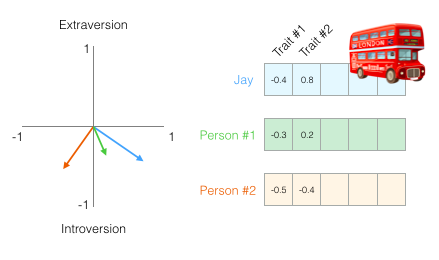
- 벡터를 다룰 때 유사성 점수를 계산하는 일반적인 방법은 코사인 유사도 입니다

-
Person #1은 성격상 나와 더 유사합니다. 같은 방향을 가리키는 벡터 (길이도 역할을 함)는 코사인 유사도 점수가 높습니다
- 하지만 두 차원만으로는 사람들이 얼마나 다른지에 대한 충분한 정보를 포착할 수 없습니다
-
수십년 동안의 심리학 연구로 다섯가지 주요 성격(많은 하위 특성)이 나타났습니다.
- 따라서 비교할 때 다섯가지 차원을 모두 사용합시다

-
5차원의 문제는 2차원으로 깔끔하게 시각화 할 수 있는 능력을 잃는다는 것입니다
- 종종 생각해야 하는 문제인데, 고차원 공간에서 기계학습에서 흔히 발생하는 도전입니다
- 하지만 여전히 좋은 점은 코사인 유사도가 효과가 있다는 것이고 여러가지 차원에서 작동되는 일입니다
-
코사인 유사도는 여러 차원에 대해 작동함
- 비교되는 것들에 대한 더 높은 많은 정보량(고차원) 표현에 기초하여 계산되기 때문에 훨씬 더 나은 점수를 얻을 수 있습니다
-
해당 섹션의 끝에서 두 가지 핵심 아이디어를 제시하는데
- 사람(그리고 사물)을 숫자의 벡터로 표현할 수 있음
- 서로 유사한 벡터가 얼마나 비슷한지 쉽게 계산할 수 있음
Word Embeddings
-
훈련된 단어벡터 예제(Word Embeddings이라고도 불림)를 살펴보고 흥미로운 속성을 살펴볼 수 있습니다
-
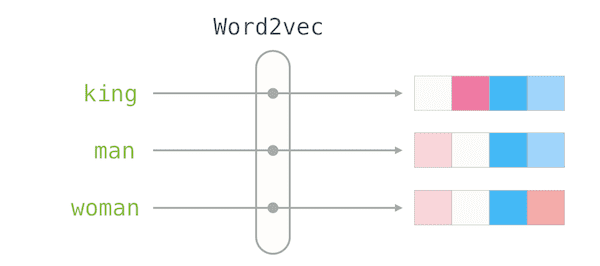
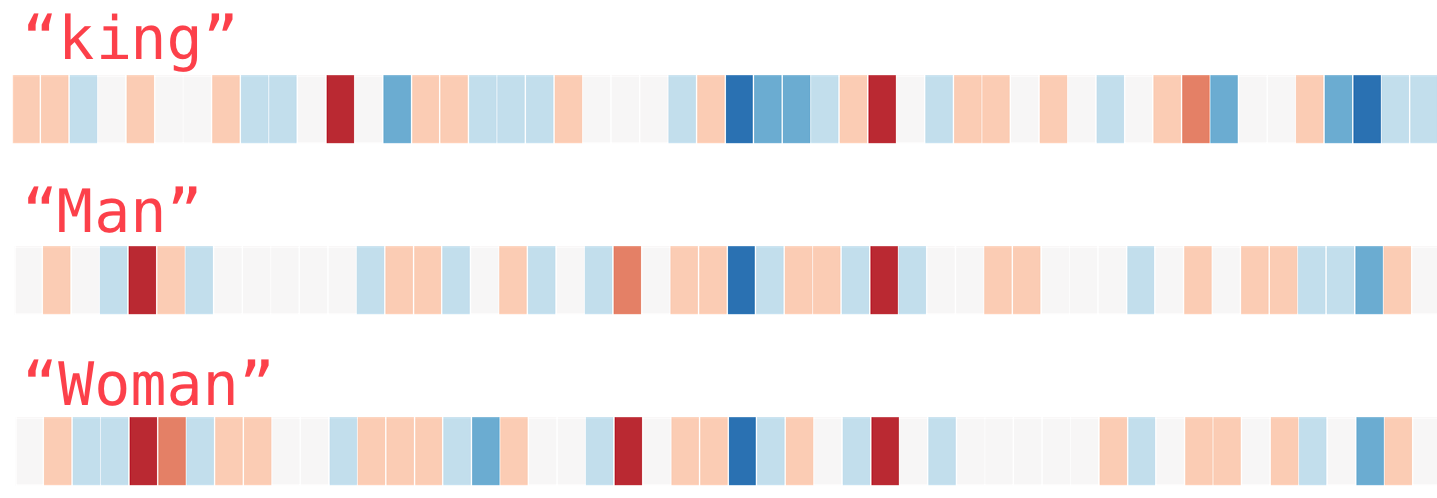
“왕”(위키피디아 데이터로 훈련된 GloVe 벡터)이라는 단어에 포함된 벡터 값은 다음과 같음
[0.50451, 0.68607, -0.59517, -0.022801, 0.60046, 0.08813, 0.47377, -0.61798, -0.31012, -0.066666, 1.493, -0.034173, -0.98173, 0.68229, 0.812229, 0.81722, -0.51722, -744.5.4 1503, -0.55809, 0.66421, 0.1961, -0.1495, -0.033474, -0.30344, 0.41177, -2.223, -1.0756, -0.343554, 0.33505, 1.9927, -0.042434, -0.64519, 0.72519, 0.71419, 0.714319, 0.71419 9159, 0.16754, 0.34344, -0.25663, -0.8523, 0.1661, 0.40102, 1.1685, -1.0137, -0.2155, 0.78321, -0.91241, -1.6626, -0.64426, -0.542102]
-
50개의 숫자 목록(값)을 보고는 많은 것을 알 수 없습니다
- 하지만 다른 단어 벡터와 비교할 수 있도록 조금 시각화해보면 (모든 숫자를 한 줄로 놓으면)
- 셀의 값을 기준으로 셀을 색칠합시다 (2에 가까울 경우 빨간색, 0에 가까울 경우 흰색, -2에 가까울 경우 파란색)

- 숫자를 무시하고 벡터의 값을 나타내는 색만 바라봅시다, 이제 “왕”을 다른 단어와 대조합시다.
-
‘남자’와 ‘여성’이 ‘왕’이랑 비교해보면 어떤 단어가 훨씬 더 비슷하다는 것을 알 수 있을까요?
- 벡터 표현은 단어의 정보 / 의미 / 연관성을 상당히 포착합니다
-
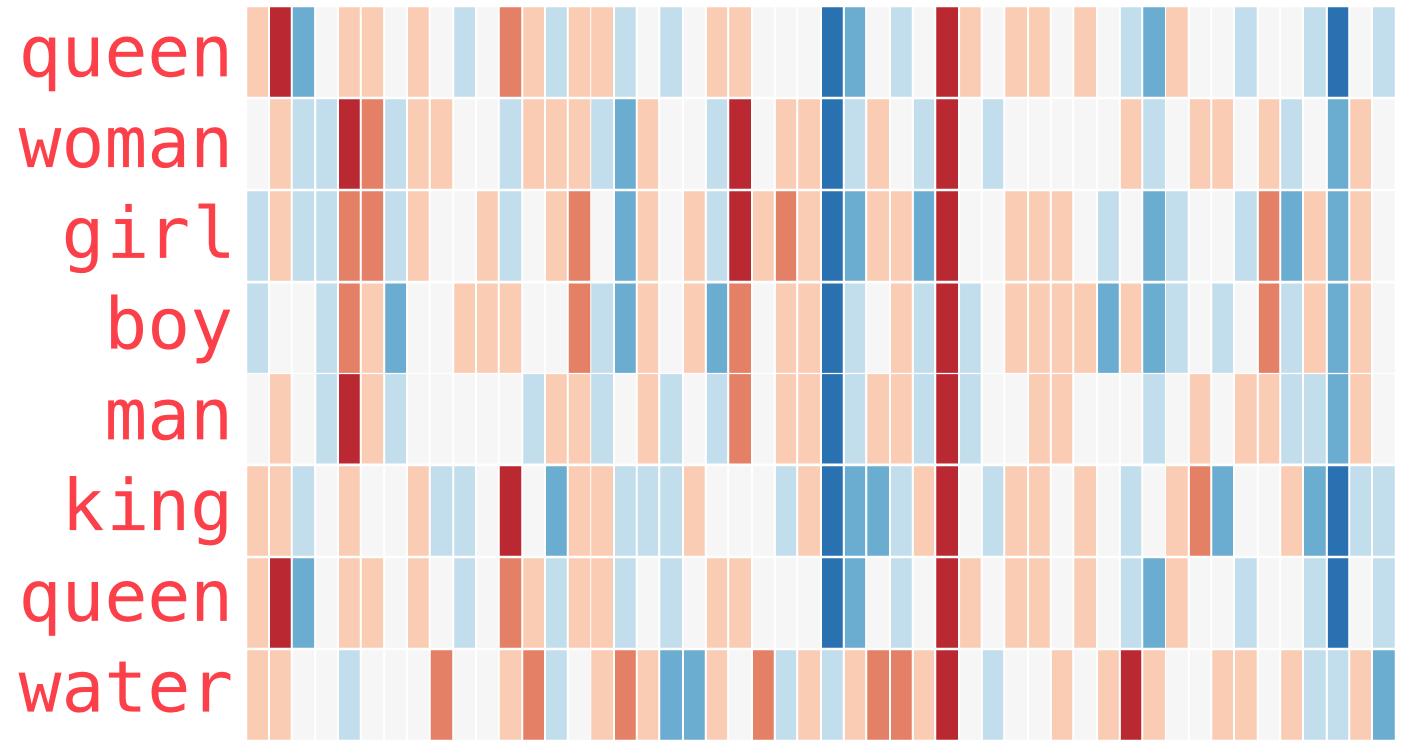
다음은 또 다른 예제 목록입니다 (유사한 색상의 열을 찾는 열을 수직으로 스캔하여 비교하십시오)
-
위 결과에서 몇 가지 유의해야 될 할 사항입니다
- 모든 단어들에서 빨간색 기둥이 있습니다. 해당 차원은 비슷하고 그리고 우리는 각 차원이 어떤 의미를 만드는지 모릅니다.
- woman & girl의 유사성, man & boy의 유사성을 알 수 있습니다
- “boy의”과 “girl의”는 서로 비슷하지만 “woman” 또는 “man”와는 다릅니다. 청소년에 대한 모호한 개념을 나타내는 것이 가능할까요?
- 마지막 단어를 제외한 모든 단어는 사람들을 나타내는 단어입니다. 범주들 사이의 차이를 보여주기 위해 물체(물)를 추가했습니다. 예를 들어, 파란색 기둥이 “water”을 포함하기 전에 아래로 내려가고 멈추는 것을 볼 수 있습니다.
- ‘왕’과 ‘여왕’이 서로 비슷하고 다른 모든 것과 구별되는 분명한 컨테스트가 있습니다. 이러한 막연한 것들의 로열티 개념을 나타낼 수 (부호화) 있을까요?
Analogies
-
임베딩의 믿을 수 없는 속성을 보여주는 유명한 예는 유추의 개념입니다
- 워드 임베딩들을 더하고 빼면서 흥미로운 결과를 얻을 수 있습니다. 가장 유명한 예시는 “king” - “man” + “woman”이라는 수식 입니다
-
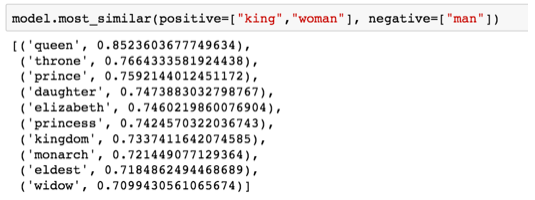
파이썬의 Gensim 라이브러리를 사용하여 단어 벡터를 추가하고 뺄 수 있으며 결과 벡터와 가장 유사한 단어를 찾을 수 있습니다
- 이미지는 가장 유사한 단어의 목록을 보여주며 각 단어는 코사인 유사도를 가집니다
- 이전에 했던 것처럼 비유를 시각화할 수 있음
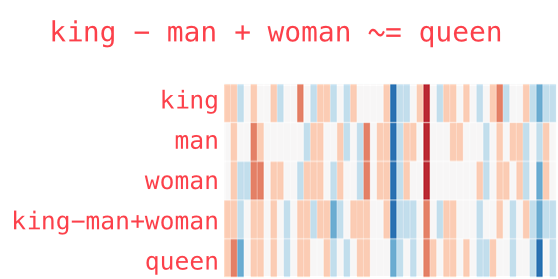
- “왕 - 남자 + 여자”의 결과 벡터는 정확히 “여왕”과 같지않지만 “여왕”은 우리가 컬렉션에 가지고 있는 40만 단어 임베딩에서 가장 가까운 단어입니다
-
이제 훈련된 단어 임베딩을 살펴보았으니 훈련 과정에 대해 더 자세히 알아보자.
- 하지만 word2vec에 도달하기 전에 우리는 단어 임베딩의 개념적인 부모 모델인 신경망 언어 모델을 살펴봐야 합니다.
Language Modeling
-
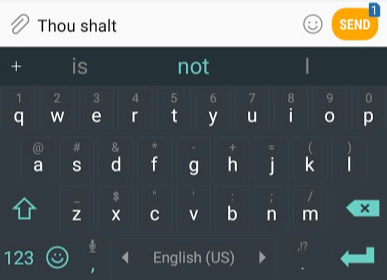
NLP 응용 프로그램의 예를 제시하고자 할 때 가장 좋은 예 중 하나는 스마트폰 키보드에서 다음 단어를 예측하는 기능입니다
- 수십억명의 사람들이 매일 수백 번 사용하는 특징 기능입니다
-
다음 단어 예측은 언어 모델에서 해결할 수 있는 작업
- 언어 모델은 단어 목록(두 단어로 했을 때)을 가져가서 단어 뒤에 오는 단어를 예측할 수 있음
- 스크린샷에서 우리는 이 두 가지 녹색 단어(Thou shalt)를 취하여 제안 목록을 반환하는 모델로 생각할 수 있음

- 단어 예측 모델을 블랙박스처럼 볼 수 있다고 생각할 수 있습니다.

-
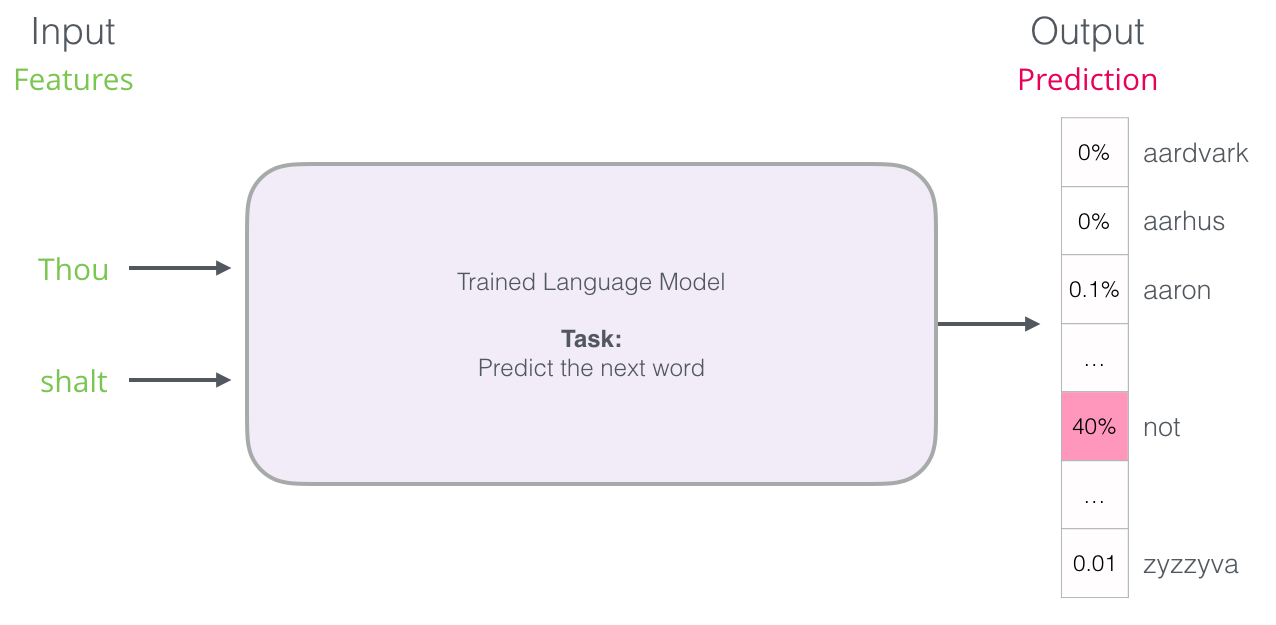
그러나 실제로는 모델이 하나의 단어만 출력하지는 않음
- 실제로는 알고 있는 모든 단어에 대해 확률 점수를 산출합니다(모델의 ‘어휘’는 수천 단어 ~ 백만 단어가 넘습니다)
- 키보드 응용 프로그램은 가장 높은 점수를 가진 단어를 찾아 사용자에게 제시해야 합니다
-
신경망 언어 모델의 출력은 모델이 알고 있는 모든 단어에 대한 확률 점수
- 확률을 백분율로 나타내고 있지만, 실제로 40%는 출력 벡터에서 0.4로 표시
-
훈련을 받은 후 초기 신경망 언어 모델 (Bengio 2003)은 세 단계로 예측을 계산합니다
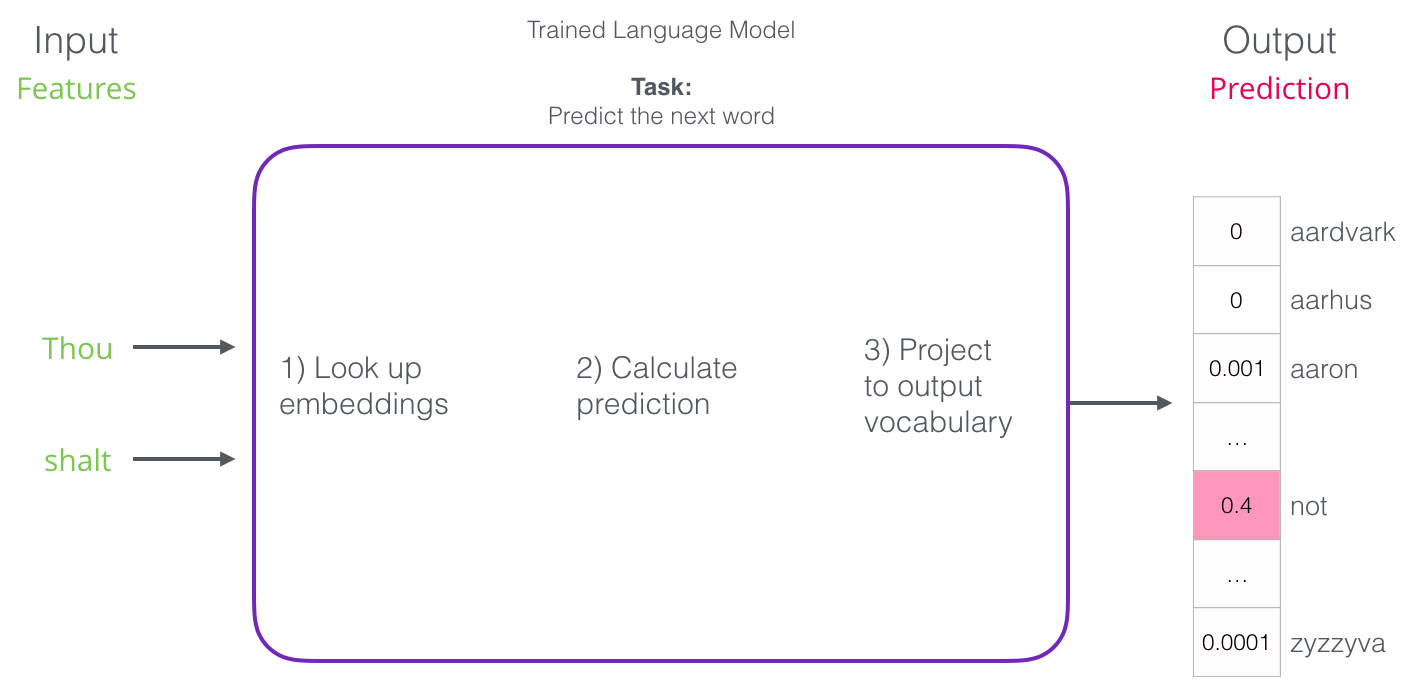
-
첫 번째 단계는 임베딩에 대해 논의할 때 가장 관련이 있습니다
- 훈련 과정의 결과 중 하나는 어휘에 각 단어에 대한 포함이 포함된 행렬이었습니다
- 예측시간 동안 입력 단어의 임베딩을 찾아 예측을 계산하는 데 사용합니다
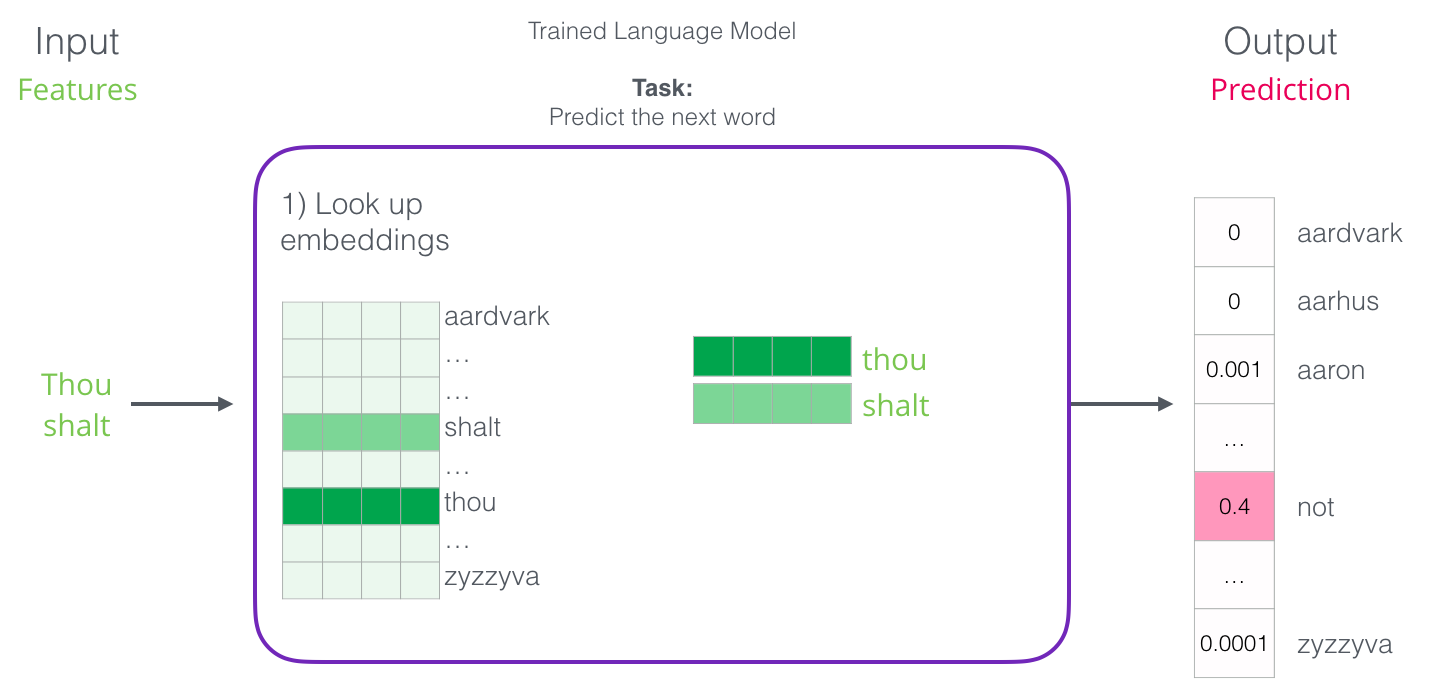
- 임베딩 매트릭스가 어떻게 개발되었는지 더 자세히 알아보기 위해 훈련 과정을 살펴보자.
Language Model Training
-
언어 모델은 대부분의 다른 기계학습 모델보다 큰 이점을 가지고 있음
- 장점은 실행중인 텍스트에서 그들을 훈련시킬 수 있다는 것입니다
-
주변에 두고 있는 모든 책, 기사, 위키피디아 내용, 그리고 다른 형태의 텍스트 데이터를 생각해보자
- 대조적으로 손으로 만든 feature와 특수하게 수집된 데이터가 필요한 많은 다른 기계학습 모델과 대조됨
-
단어는 옆에 나타나는 다른 단어를 보면서 모델에 의해 내장됩니다
- 많은 텍스트 데이터를 얻을 수 있습니다 (예를 들어 위키피디아의 모든 기사)
- 모든 텍스트에 대해 윈도우 창 (예 : 세 단어)을 가지고 있습니다.
- 슬라이딩 윈도우에서 모형에 대한 훈련 샘플이 생성됩니다
-
텍스트에 대해서 윈도우 창이 움직이면서 모델을 훈련시키는데 사용하는 데이터 세트를 생성함
- 어떻게 그렇게 되었는지 정확히 살펴보려면 슬라이딩 윈도우가 이 문구를 어떻게 처리하는지 살펴보자.
-
시작할 때, 윈도우 창은 문장의 처음 세 단어에 있음

- 처음 두 단어를 특징으로 삼고 세 번째 단어는 레이블로 사용함

- 창을 다음 위치로 이동하고 두 번째 샘플을 만듭니다.
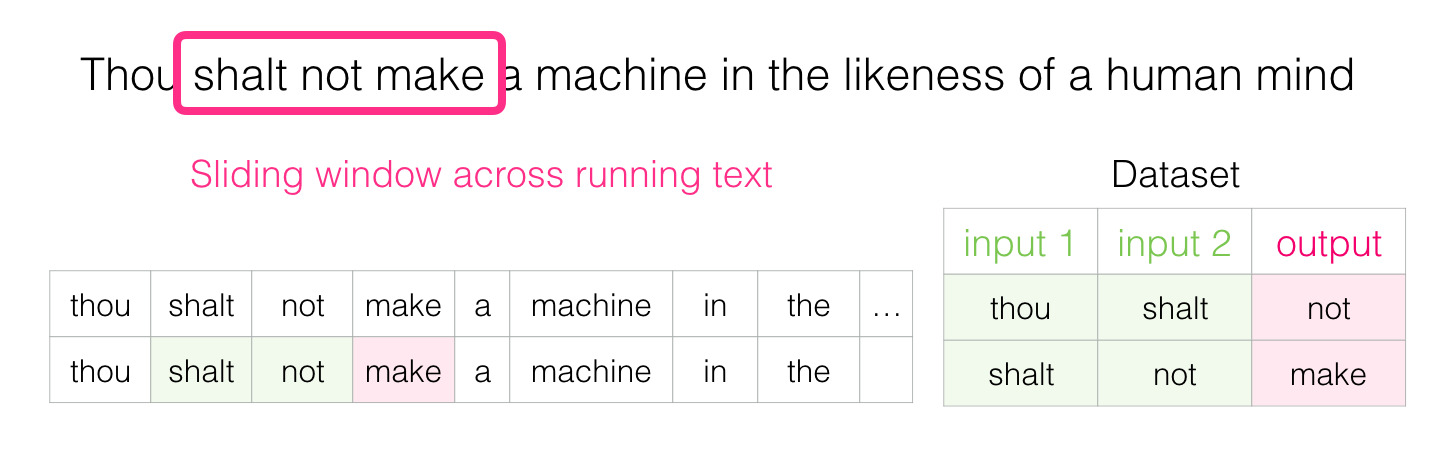
- 그리고 곧 우리는 더 큰 데이터 세트를 갖게됩니다. 그 중 단어는 다른 단어 쌍 뒤에 나타나는 경향이 있음
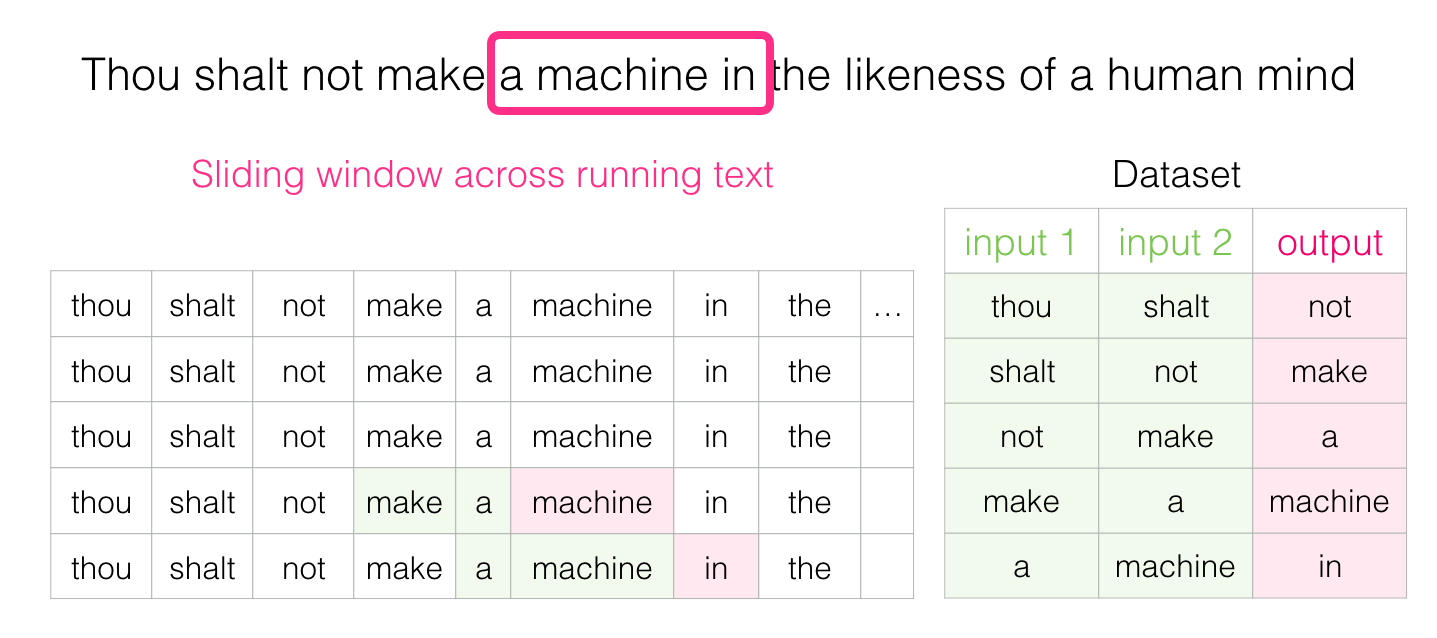
- 실제로는 우리가 창문을 이동하는 동안 모델들이 훈련받는 경향이 있음
-
하지만 ‘데이터셋 생성’ 단계를 훈련 단계와 논리적으로 분리하는 것이 가능하다는 것을 알게 되었습니다
- 언어 모델링에 대한 신경망 기반 접근법을 제외하고 N-grams라는 기술이 일반적으로 언어 모델을 훈련시키는 데 사용되었음
-
N-grams에서 신경망 모델로의 전환이 실제 제품에 어떻게 반영되는지 보려면, 블로그 포스트가 신경망 언어 모델을 소개하고 이전 N-grams 모델과 비교하고 있습니다
- 블로그 예는 marketing speech에서 임베딩의 알고리즘 속성을 어떻게 설명할 수 있는지 보여주기 때문에 좋습니다
Look both ways
- 게시물의 앞 부분에서 알 수 있는 정보로 빈 칸을 채우십시오.

-
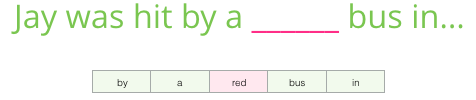
당신에게 준 맥락은 빈 단어(그리고 ‘버스’에 대한 이전 언급)보다 다섯 단어 앞선 것
- 버스라는 단어가 빈 곳에 들어가게 될 거라고 대부분의 사람들이 짐작할 것입니다
- 하지만 내가 한 가지 더 정보를 주면 어떨까? 빈 단어 뒤에 한 단어가 있다면, 그 대답이 바뀔까?

-
다음은 빈칸에 들어가야 할 것을 완전히 바꾼다
- 이제 빨간색이라는 단어가 공백으로 들어갈 가능성이 가장 높다.
- 해당 예제로 배우는 것은 특정 단어의 전후 단어를 보고 가치를 판단할 수 있음
-
두 가지 방향(우리가 추측하는 단어의 왼쪽과 오른쪽에 있는 단어)을 모두 설명하면 단어가 더 잘 embedding된다는 사실이 밝혀졌음
- 문제를 설명하기 위해 모델을 훈련하는 방식을 어떻게 조정할 수 있는지 보자!
Skipgram
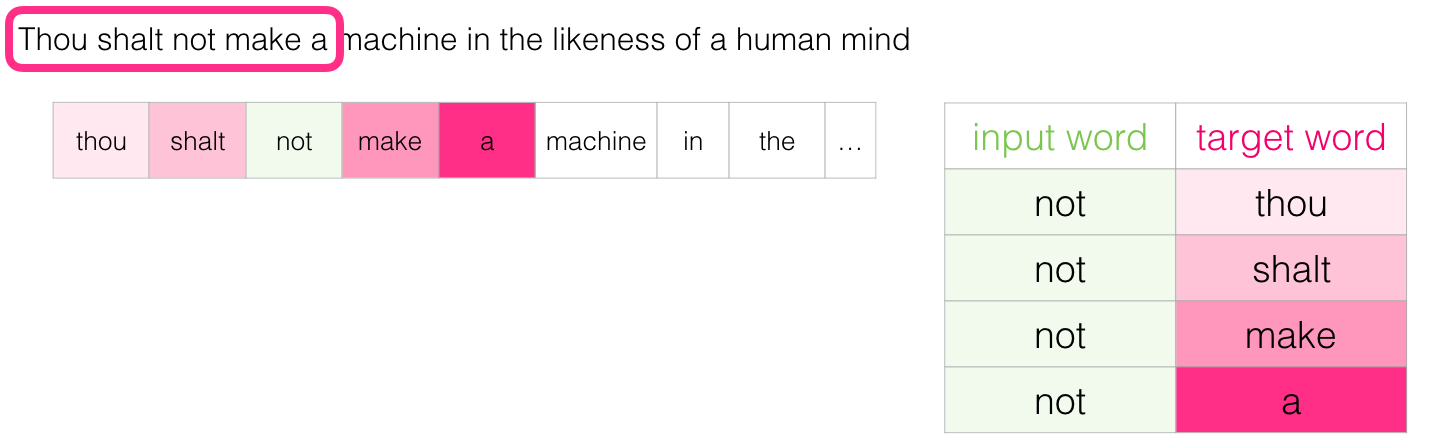
- 목표 단어(target word) 전 두 단어만 보는 대신 목표 단어 후에 두 단어만 볼 수도 있음
- 이렇게 하면, 모델을 실제로 구축하고 훈련하는 데이터 세트는 다음과 같이 보일 것

-
Continuous Bag of Words 아키텍처라고 불리며 word2vec 논문 중 하나에 설명되어 있습니다
-
제안된 또 다른 아키텍처는 방식을 약간 다르게 합니다
- 다른 아키텍처는 문맥(이전과 후에 단어)을 기반으로 단어를 추측하는 대신 현재 단어를 사용하여 이웃 단어를 추측하려고 합니다
- 훈련 텍스트에 대해 윈도우를 다음과 같이 생각할 수 있습니다

-
녹색 슬롯의 단어는 입력 단어이고 각 분홍색 상자는 가능한 출력
- 분홍색 상자는 서로 다른 음영을 가지고 있습니다.
- 슬라이딩 창은 실제로 훈련 데이터 세트에 4 개의 개별 샘플을 생성하기 때문
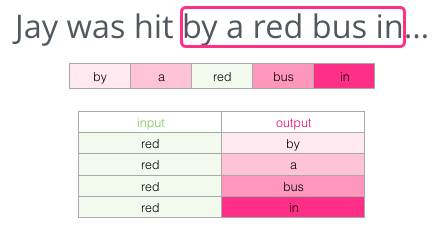
- 해당 방법을 Skipgram 아키텍처라고 합니다. 우리는 슬라이딩 윈도우를 다음과 같이 시각화할 수 있습니다.

- 이렇게 하면 훈련 데이터 세트에 네 가지 샘플이 추가됨
- 창(window)을 다음 위치로 이동합니다.
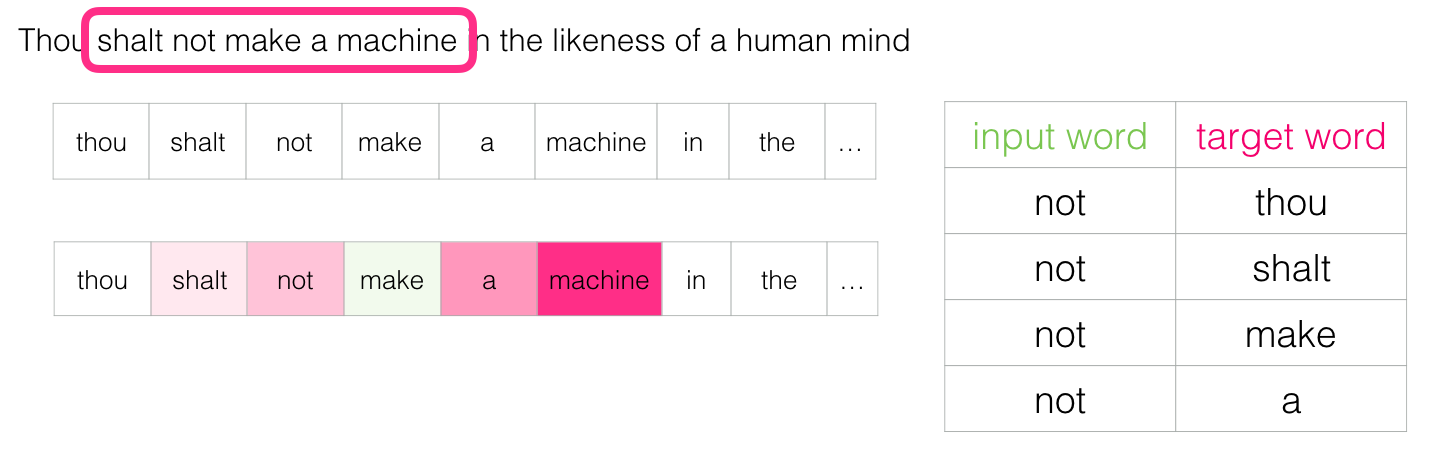
- 다음 네 가지 데이터 예제가 생성됩니다

- 몇 가지를 수행한 후, 우리는 더 많은 데이터를 가지게 됨
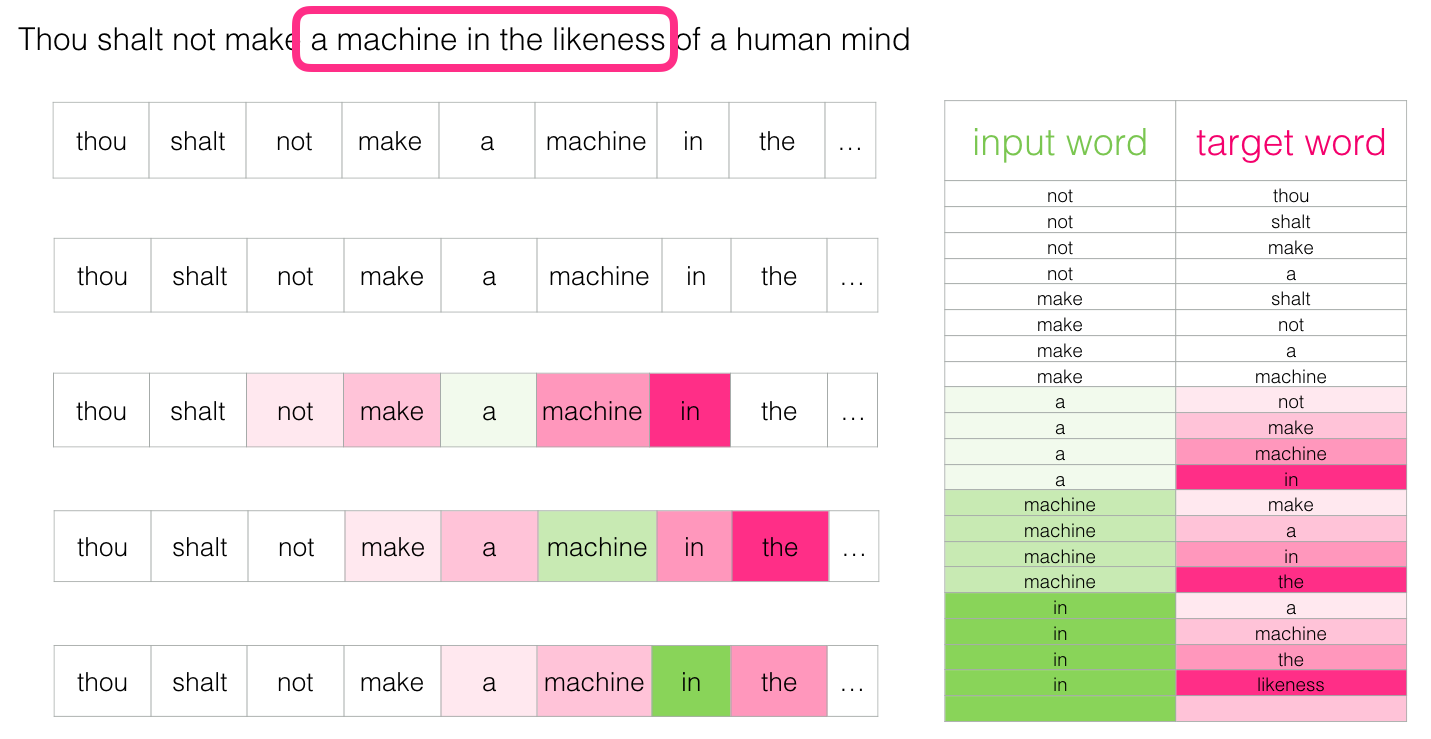
Revisiting the training process
- 기존 창을 움직이면서 text에서 추출한 skipgram 훈련 데이터 세트를 가지고 있으므로, 해당 데이터를 사용하여 이웃 단어를 예측하는 기본 신경망 언어 모델을 훈련시키는 방법을 살펴보자
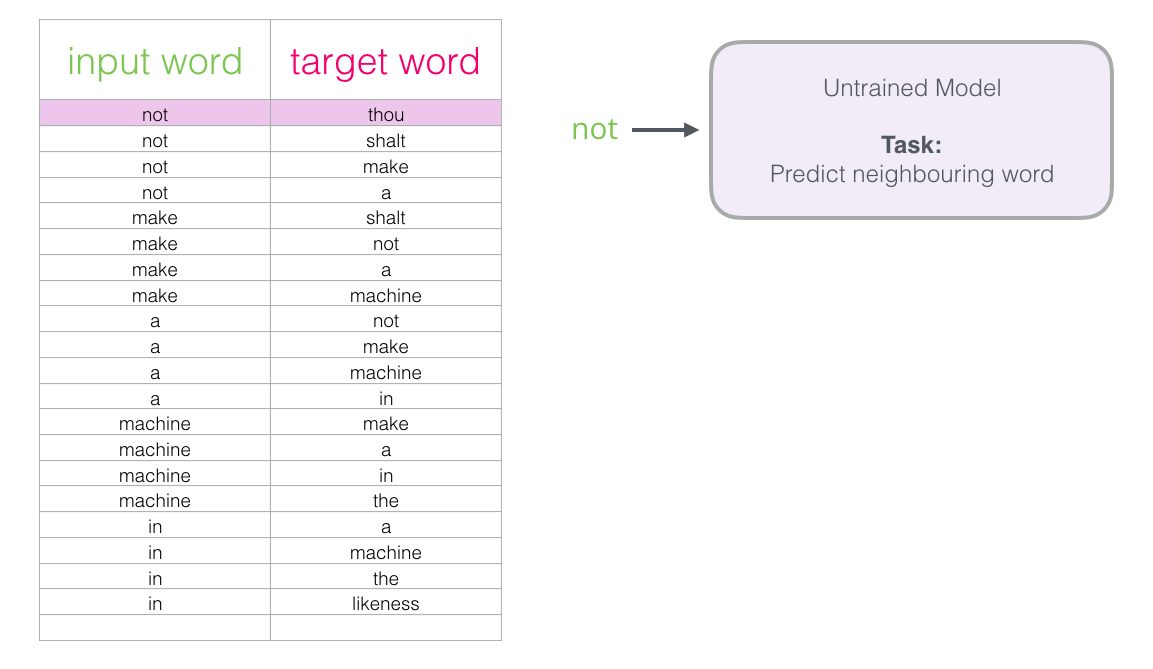
-
데이터 세트의 첫 번째 표본부터 시작합니다
- 해당 특징을 잡아 훈련받지 않은 모델에게 적절하게 이웃 단어를 예측하도록 요청
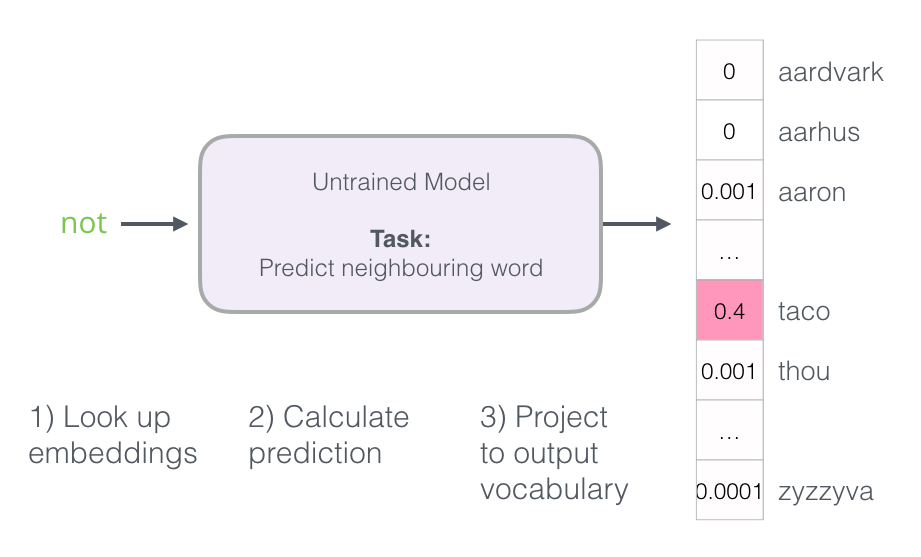
- 모델은 세 단계를 수행하고 예측 벡터를 출력함 (어휘의 각 단어에 할당 된확률)
-
이 단계에서는 모델이 훈련되지 않았기 때문에 예측이 틀릴 것이 분명함. 하지만 그건 괜찮다.
- 왜냐면 추측해야할 단어, 현재 모델을 훈련시키기 위해 사용하고 있는 행의 답지(레이블, 출력 셀)을 알고 있기 때문에
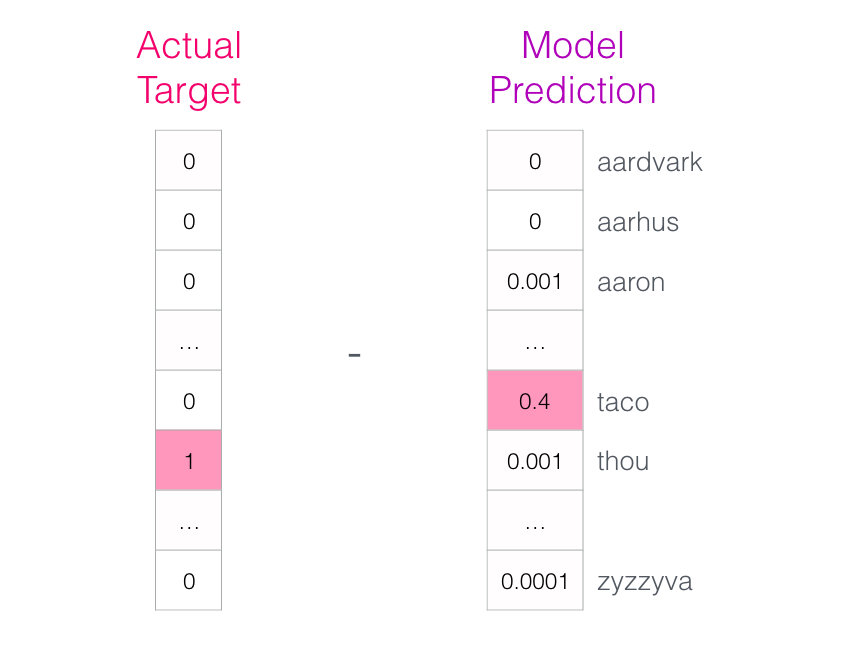
- 모델이 얼마나 떨어져 있었습니까? 우리는 두 벡터를 빼서 error 벡터를 만듦
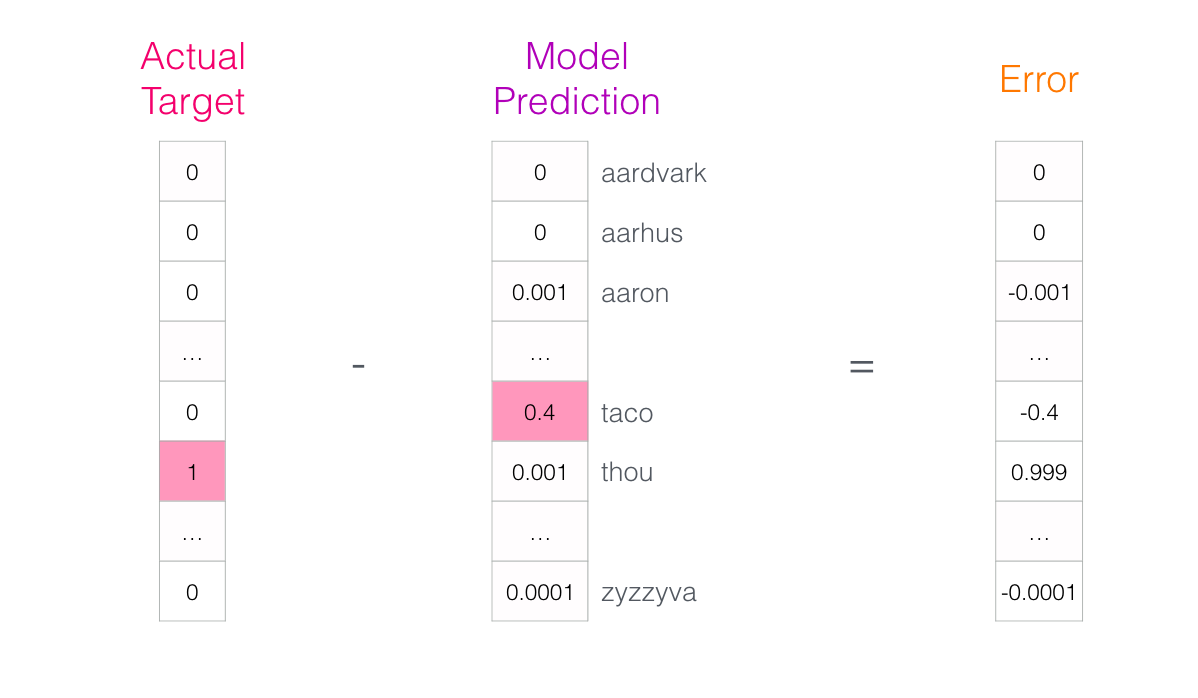
- 에러 벡터는 이제 모델을 업데이트하는 데 사용할 수 있으므로 다음 번에는 입력이 not인 경우 추측할 가능성이 약간 더 커집니다
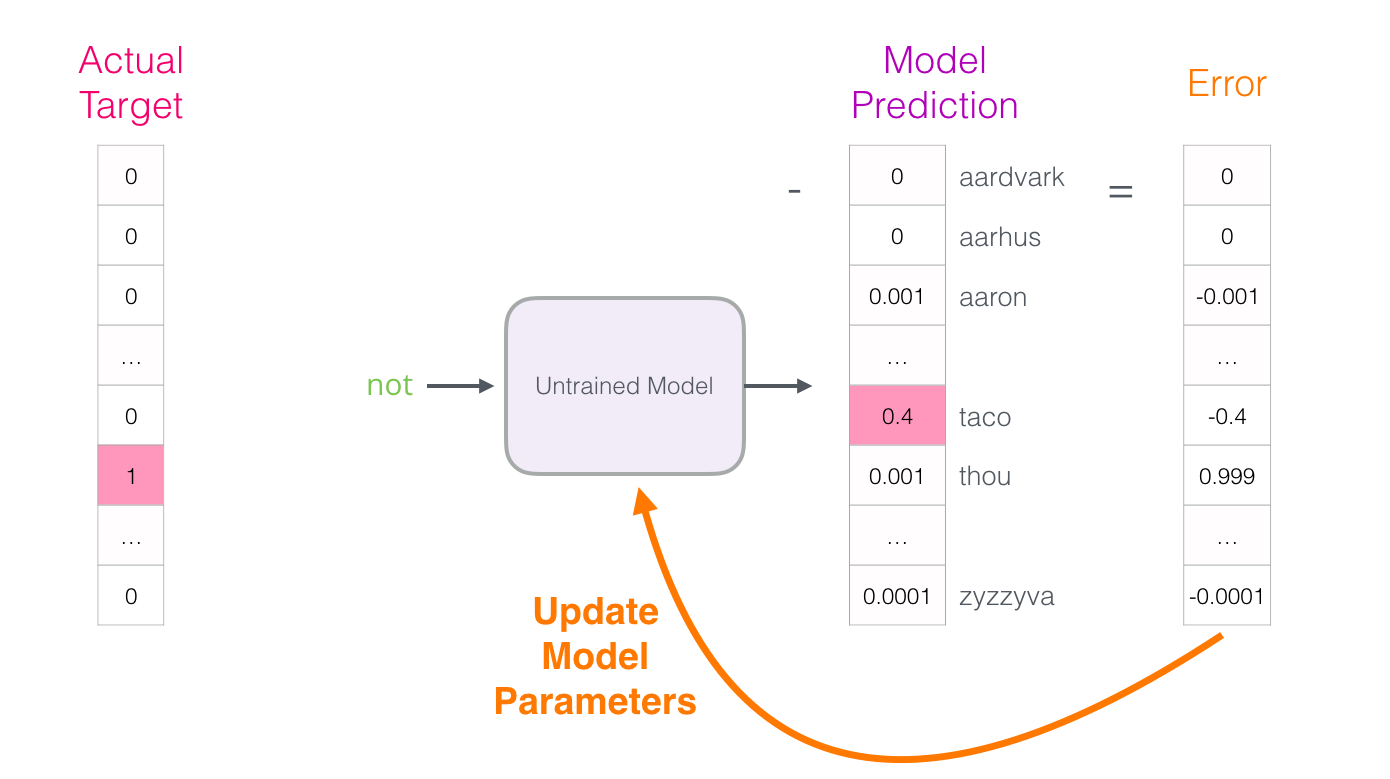
-
훈련의 첫 단계를 마무리, 데이터 세트의 다음 샘플과 같은 과정을 거쳐 데이터 세트의 샘플을 모두 다 포함될 때까지 계속 진행합니다
-
훈련 한 번의 epochs를 마무리.
- 여러 번의 epochs에 걸쳐 다시 한 번 훈련하고, 다음 훈련된 모델을 가지고 임베딩 매트릭스를 추출하여 다른 응용 프로그램에 사용할 수 있음
-
이 내용이 과정에 대한 이해를 확장하는 반면, word2vec이 실제로 어떻게 훈련되었는지 알 수 있는 건 여전히 아닙니다. 몇 가지 핵심적인 아이디어들을 놓치고 있습니다
Negative Sampling
- 신경망 언어 모델이 예측을 계산하는 방법의 세 단계를 상기하라.
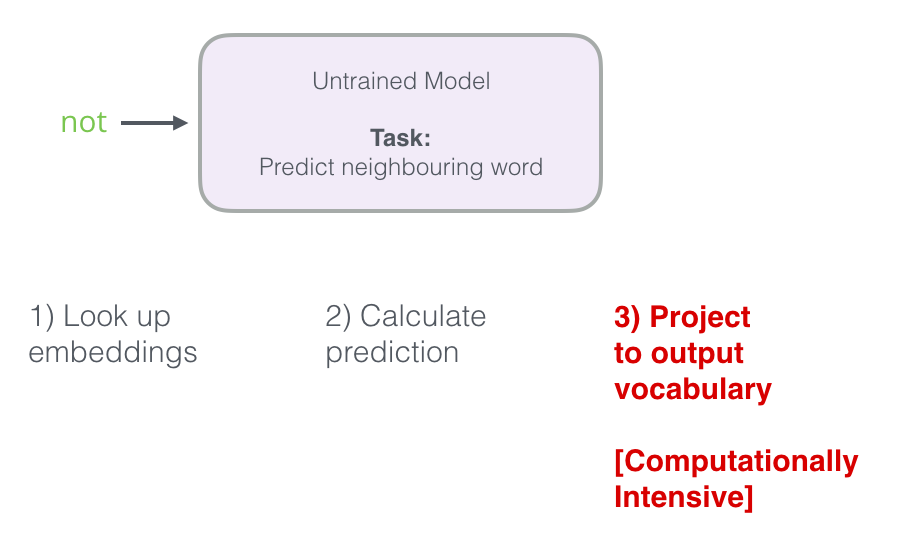
-
세 번째 단계는 계산 상의 관점에서 보면 매우 비쌉니다
- 특히 데이터 세트에 있는 모든 훈련 샘플(수천만번)에 대해 한 번만 해볼 수 있다는 사실을 알고 있기 때문에 성능을 향상시키기 위해 무언가를 해야 합니다
-
한 가지 방법은 목표를 두 단계로 나누는 것이다.
- 고품질의 단어 임베딩을 만들어라(다음 단어 예측에 대해서는 걱정하지 마라)
- 고품질 임베딩을 사용하여 언어 모델을 교육합니다 (다음 단어 예측을 수행하십시오)
-
1단계에 집중할 것이다. 이 포스트에서 임베딩에 초점을 맞추고 있다.
- 고성능 모델을 사용하여 고품질 임베딩을 생성하기 위해 모델의 작업을 이웃 단어 예측에서 전환할 수 있음
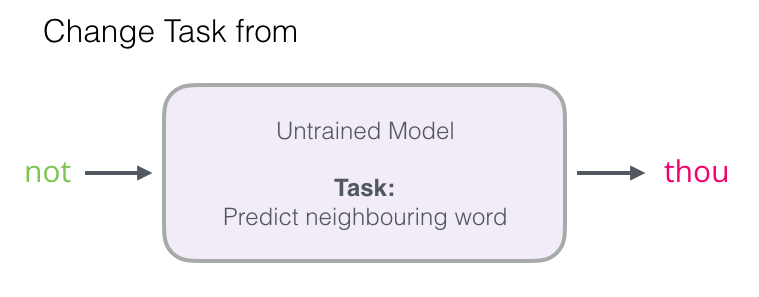
-
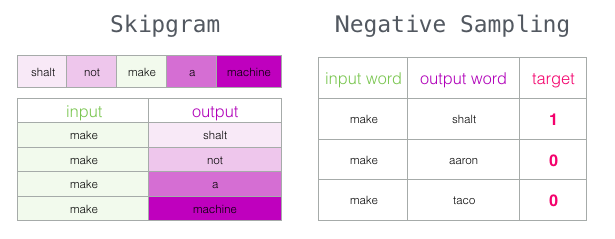
입력과 출력 단어를 사용하는 모델로 전환하고, 이웃인지 아닌지 나타내는 점수를 산출함
- “이웃이 아닌” 것은 0, “이웃”은 1

-
간단한 스위치는 우리가 필요한 모델을 신경망에서 로지스틱 회귀 모델로 변경하므로 계산하는 것이 훨씬 간단하고 빨라짐
-
이 스위치는 데이터 세트의 구조를 전환해야 함
- 레이블은 이제 값 0 또는 1이 있는 새로운 열
- 추가한 모든 단어가 이웃이기 때문에 그들은 모두 1이 될 것
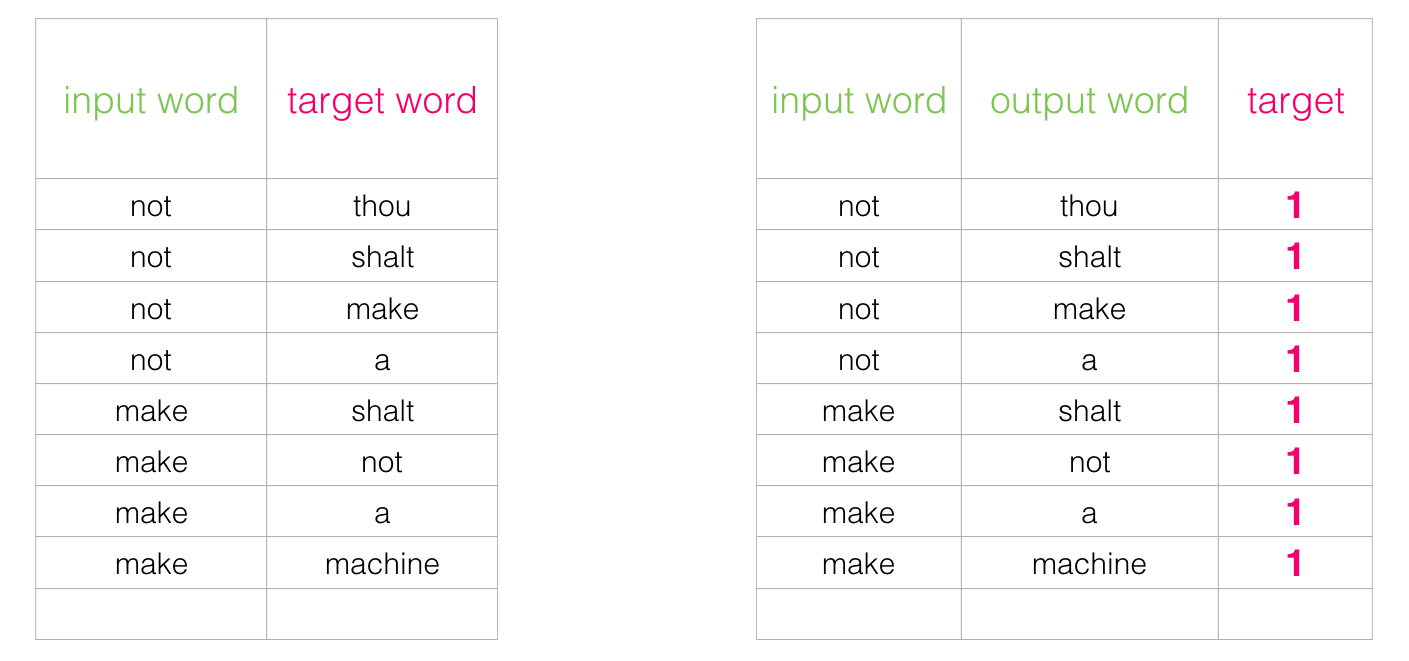
- 몇 분 안에 수백만 가지 예를 처리하는 놀라운 속도로 계산할 수 있습니다
-
하지만 우리가 해결해야될 일이 하나 있습니다
- 모든 예가 긍정적이라면(목표: 1) 우리는 항상 1을 반환하는 smartass(수재) 모델의 가능성을 열어 100% 정확도를 달성하지만 아무것도 배우지 않는 쓰레기가 됨
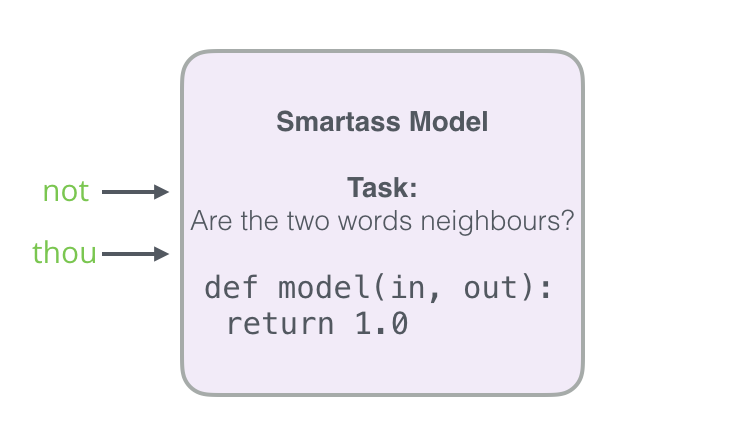
-
해당 문제를 해결하기 위해 데이터 세트에 negative sample을 도입해야 함
- 이웃이 아닌 단어 샘플입니다
- 모델은 샘플에 대해 0을 반환해야 합니다. 이제 이 모델은 해결하기 위해 열심히 노력해야 하지만 여전히 빠른 속도로 계산하는 도전 과제

-
데이터 집합의 각 표본에 대해 음수 예제를 추가합니다. 같은 입력 단어와 0 레이블을 가지고 있음
- 하지만 우리는 출력 단어로 무엇을 채울까? 무작위로 어휘에서 단어를 샘플링
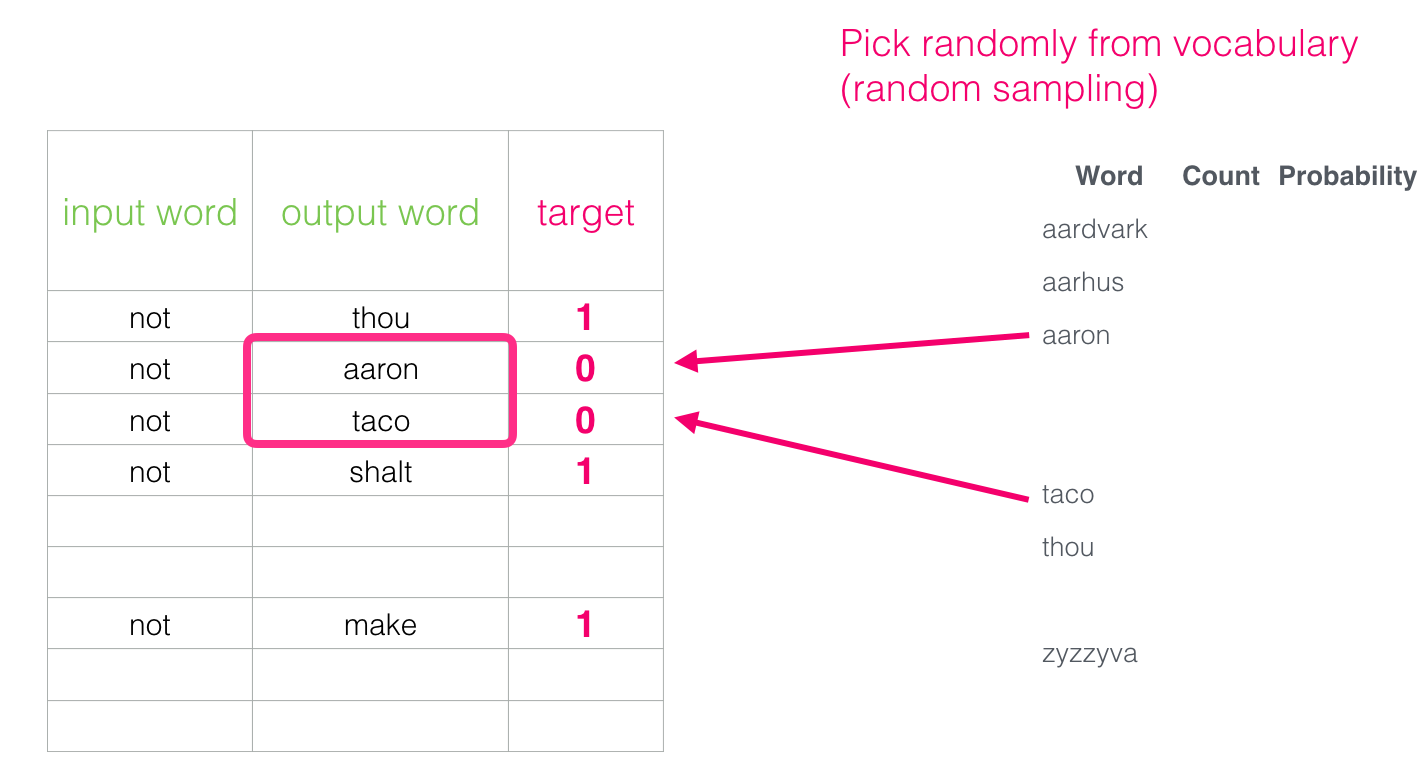
- 해당 아이디어는 Noise-contrastive estimation에서 영감을 얻었습니다
- 실제 신호(이웃 단어의 긍정적인 예)와 잡음(이웃 단어가 아닌 무작위로 선택된 단어)을 대조하고 있습니다
- 해당 방법은 계산 및 통계 효율성의 큰 절충을 가져옴
Skipgram with Negative Sampling (SGNS)
-
이제 두 가지 핵심 아이디어를 담은 word2vec 알고리즘을 다루었습니다.
- skipgram with negative sampling
Word2vec Training Process
-
실제 word2vec 훈련 과정을 자세히 살펴볼 수 있음
-
훈련 과정이 시작되기 전에 우리는 모델에 대해 훈련하는 텍스트를 미리 처리합니다
- 이 단계에서 어휘의 크기를 결정한다(이를 ‘vocab size’라고 부르고, 이를 ‘10,000’라고 가정)
-
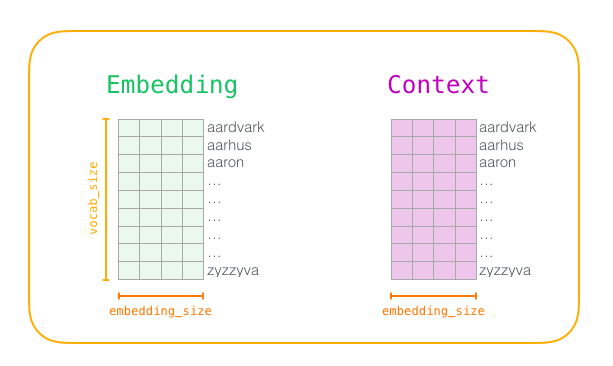
훈련 단계가 시작될 때 두 개의 행렬을 만듭니다
- 즉, 임베딩 매트릭스와 컨텍스트 매트릭스입니다
- 두 행렬은 우리 어휘에 각 단어에 대한 임베딩을 가지고 있습니다
- 그래서 vocabsize는 그 차원 중 하나, 두 번째 차원은 각 임베딩이 얼마나 지속될지 나타내는 것 (embeddingsize = 300은 공통된 값이지만, 이 게시물에서 50의 예를 살펴봄)
-
훈련 과정이 시작될 때, 우리는 임의의 값으로 행렬을 초기화함
- 훈련 과정을 시작. 각 훈련 단계에서 하나의 긍정적인 예와 그에 관련된 부정적인 예들을 취합니다
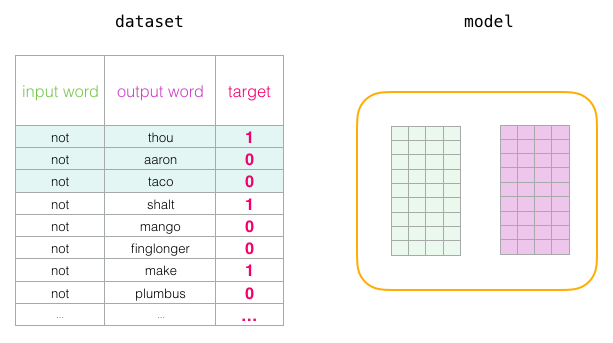
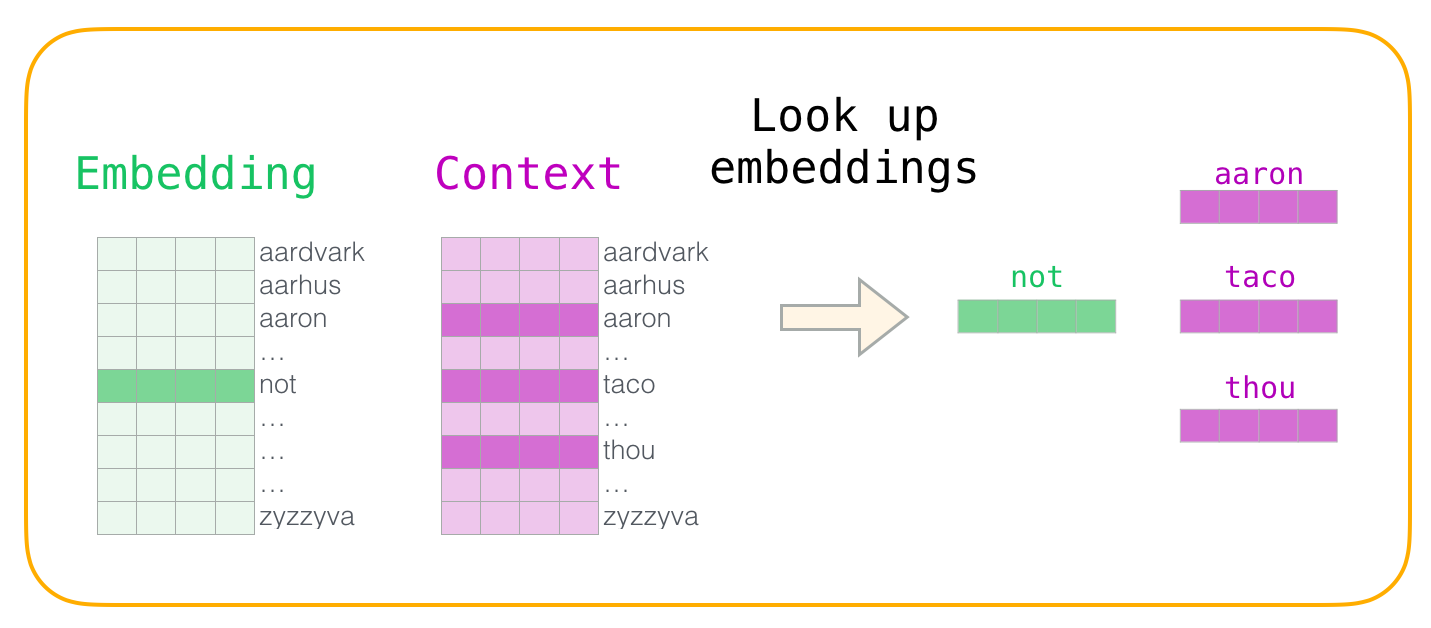
- 네 가지 단어를 가지고 있습니다 : 입력 단어가 아닌 출력 / 컨텍스트 단어 : thou (실제 이웃), aaron 및 taco (네거티브 예). 우리는 그들의 embeddings을 찾아서 살펴보기 시작합니다
- 입력 단어를 찾으려면 매트릭스를 살펴보자. 문맥 단어의 경우 컨텍스트 행렬을 찾습니다
-
다음 각 컨텍스트 임베딩에 embeddings된 입력 내적을 취함
- 각 숫자는 입력과 컨텍스트 임베딩의 유사성을 나타냄
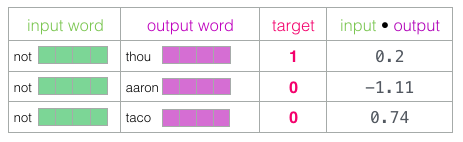
-
점수를 확률처럼 보이는 것으로 전환할 수 있는 방법이 필요
- 모두 postive 하고 0과 1 사이의 값을 가져야 합니다. 시그모이드 함수로 해당 값을 계산합니다
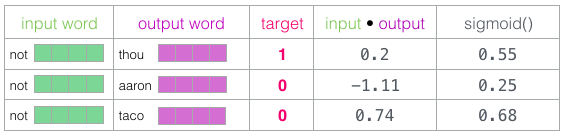
-
시그모이드 연산의 출력을 이 예제의 모델 출력으로 처리할 수 있습니다
- 타코가 가장 높은 점수를 가지고 있고 아론은 시그모이드 작업 전후에 가장 낮은 점수를 가지고 있음을 알 수 있음
-
훈련받지 않은 모델이 예측했고, 우리가 비교할 실제 목표 레이블을 가지고 있으므로 모델의 예측에 에러가 얼마나 많은지 계산해봅시다
-
목표 레이블에서 시그모이드 점수를 빼는 것
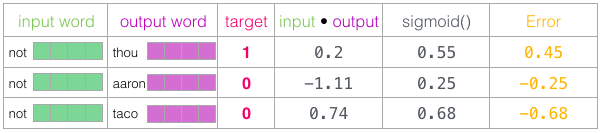
- 이제 에러 점수를 사용하여 not, thou, aaron 및 taco의 임베딩을 조정하여 다음번에 계산할 때는 결과가 목표 점수에 더 가까워짐

-
훈련 단계를 마무리하면 해당 단계에 관련 단어에 대해 약간 더 나은 embedding이 나옵니다
- 이제 우리는 다음 단계(다음 postive 표본과 관련된 negative 표본)을 가지고 같은 과정을 다시 시작
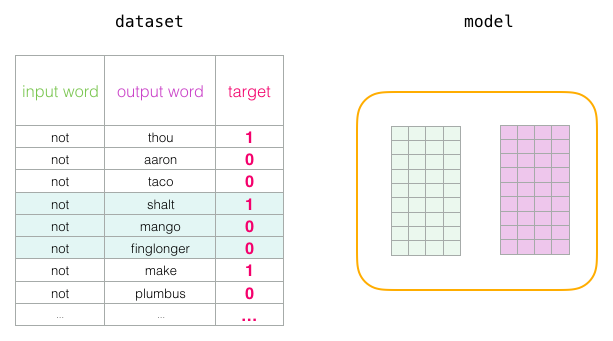
-
전체 데이터 세트를 여러 번 순환하는 동안 임베딩은 계속 개선됩니다
- 훈련 과정을 중단하고 컨텍스트 행렬을 버리고 다음 작업을 위해 미리 훈련된 임베딩으로 Embeddings 행렬을 사용할 수 있음
Window Size and Number of Negative Samples
- word2vec 훈련 프로세스의 두 가지 주요 하이퍼 매개 변수는 window 크기와 negative 샘플의 수
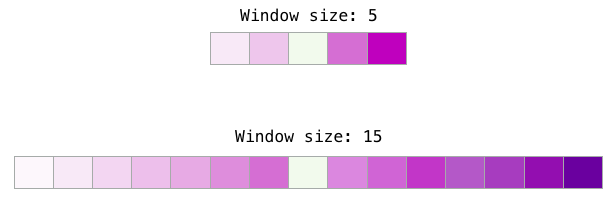
- 하나의 발견은 작은 window 크기 (2-15)가 두 임베딩 사이의 높은 유사성 점수가 단어가 서로 교환 가능하다는 것을 나타내는 임베딩으로 이어진다는 것
- 주변 단어만 볼 때 반의어가 종종 교환 가능하다는 점에 유의하십시오.
- 좋은 것과 나쁜 것은 비슷한 맥락에서 종종 나타난다). 큰 window 크기는 15-50 또는 이상
-
유사성이 단어의 관련성을 나타내는 임베딩으로 이어집니다.
- Gensim 기본 window 크기는 5입니다 (입력 단어 자체 외에도 입력 단어 뒤에 두 단어 앞).
-
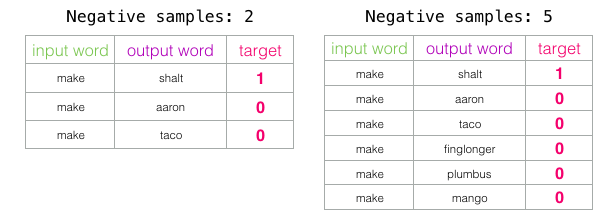
negative 샘플의 수는 훈련 과정의 또 다른 요소입니다. 원래 논문은 5-20을 많은 수의 negative 샘플로 규정합니다.
- 또한 데이터 세트가 충분히 많을 때 2-5로 충분하다고 함, 기본값은 5개의 negative 샘플
Conclusion
- Word Embedding과 word2vec 알고리즘에 대한 설명이 충분히 되었나요?
- 또한 ‘Negative 샘플링이 포함된 Skipgram’(SGNS)(추천 시스템 논문처럼)을 언급하는 논문을 읽으면 해당 개념에 대해 더 나은 이해를 갖게 되기를 바람
References & Further Readings
- Distributed Representations of Words and Phrases and their Compositionality
- Efficient Estimation of Word Representations in Vector Space
- A Neural Probabilistic Language Model
- Speech and Language Processing by Dan Jurafsky and James H. Martin is a leading resource for NLP. Word2vec is tackled in Chapter 6.
- Neural Network Methods in Natural Language Processing by Yoav Goldberg is a great read for neural NLP topics.
- Chris McCormick has written some great blog posts about Word2vec. He also just released The Inner Workings of word2vec, an E-book focused on the internals of word2vec.
-
Want to read the code? Here are two options:
- Gensim’s python implementation of word2vec
- Mikolov’s original implementation in C – better yet, this version with detailed comments from Chris McCormick.
- Evaluating distributional models of compositional semantics