참고자료
Meet Michelangelo: Uber’s Machine Learning Platform by Jeremy Hermann (Michelangelo team - Engineering Manager), Mike Del Balso (Uber Machine Learning Platform team - Product Manager)
Uber Engineering은 고객에게 완벽하고 효과적인 경험을 제공하는 기술 개발에 전념하고 있습니다. 우리는 이러한 비전을 실현하기 위해 인공 지능 (AI) 및 머신러닝에 대한 투자를 늘리고 있습니다. Uber에서 우리의 기여는 머신러닝을 민주화하고 Uber에서 승차를 요청하는 것만큼 쉽게 비즈니스의 니즈를 충족 할 수 있도록 AI를 확장하는 내부 ML-as-a-service platform인 Michelangelo를 지원하는 것입니다.
Michelangelo는 내부 팀이 Uber의 규모로 머신러닝 솔루션을 완벽하게 제작, 배포 및 운영 할 수 있게합니다. 이는 end-to-end ML workflow (데이터 관리, 모델 학습, 평가 및 배포, 예측 및 예측 모니터링)를 포괄하도록 설계되었습니다. 이 시스템은 전통적인 ML 모델, 시계열 예측 및 딥러닝을 지원합니다.
Michelangelo는 약 1년 동안 Uber의 production usecase에 사용되고 있으며 수십 개의 팀이 모델을 구축하고 배포하면서 엔지니어 및 데이터 과학자들이 머신러닝을 쓸 수 있게 하기위한 실질적인 시스템이 되었습니다. 여러 Uber 데이터 센터에 배치되어, 특수한 하드웨어를 활용하고 회사에서 로드가 가장 많은 온라인 서비스에 대한 예측을 제공합니다.
이 글에서는 Michelangelo를 소개하고, production에서의 usecase 대해 논의하며, 이 강력한 새 ML-as-a-service 시스템의 워크 플로우를 살펴 봅니다.
Motivation behind Michelangelo
Michelangelo 이전에는, Uber의 운영 규모와 스케일에 관련하여 머신러닝 모델을 만들고 배포하는데 수많은 챌린지를 마주했습니다. 데이터 사이언티스트들이 예측 모델을 만들기 위해 다양한 범위의 툴 (R, scikit-learn, custom algorithms 등) 을 사용하는 반면, 엔지니어링 팀들은 production환경에서 이러한 모델들을 사용하기 위해 일회용 시스템을 구축했습니다. 그 결과로, Uber에서 머신러닝의 영향력은 대부분 오픈소스 툴을 통해 소수의 데이터사이언티스트들과 엔지니어들이 단기간내에 만들 수 있는 것으로 제한 되었습니다.
특히, 확장성 있게 예측 데이터를 만들고 학습을 관리할 수 있는 신뢰성있고, 균일하고, 재생산 가능한 파이프라인이 없었습니다. Michelangelo 이전에는 데이터사이언티스트들의 데스크탑 머신에서 돌아갈 수 있는 크기보다 더 큰 데이터에 대해서는 모델을 학습하는 것이 불가능했고, 학습 실험 결과를 저장하고 다른 실험들과 쉽게 비교할 수 있도록 하는 표준화된 저장소가 없었습니다. 가장 중요한 것은, 대부분의 경우에서 production환경에 모델을 배포하는 확실한 경로가 없었고, 관련있는 엔지니어링 팀에서 특정 프로젝트에 대해 커스텀한 서빙 컨테이너를 만들어서 관리했습니다. 동시에, 우리는 Scully에 의해 문서화된 많은 ML anti-pattern들의 징후를 볼 수 있었습니다.
Michelangelo는 회사내 누구든 쉽게 머신러닝 시스템을 확장성 있게 만들고 동작시킬 수 있는 end-to-end 시스템을 통해, 팀끼리 사용하는 워크플로와 도구들 표준함으로써 이러한 문제들을 해결하기위해 디자인되었습니다. 우리의 목표는 당장 처한 문제들을 해결하는 것 뿐만 아니라, 비지니스와 함께 성장할 수 있는 시스템을 만드는 것입니다.
2015년 중반부터 우리가 Michelangelo를 만들기 시작했을 때, 우리는 확장성있게 모델을 학습하고 production 환경의 서빙 컨테이너에 배포하는데 따른 어려움들을 해결하는 것에서부터 시작했습니다. 그리고, 우리는 feature 파이프라인을 공유하고 관리하기에 더 용이한 시스템을 만드는 것에 집중했습니다. 최근에는 개발자의 생산성(아이디어에서 첫 production 모델로 만드는 데까지 걸리는 시간을 어떻게 빠르게 할 것이냐와 이를 빠르게 반복하는 것)을 향상시키는 데 집중하고 있습니다.
다음 section에서 우리는 어떻게 Michelangelo가 Uber의 특정 문제를 해결하기 위해 모델을 만들고 배포하는데 어떻게 사용되는지 이해하기 위해 예시 애플리케이션 하나를 살펴보려고 합니다. 우리가 UberEATS의 특정 use case를 강조하긴 했지만, 이 플랫폼은 회사 전반에 걸쳐 다양한 예측 use case를 위한 이와 비슷한 많은 모델들을 관리하고 있습니다.
Use case: Uber EATS 예상 배송 시간 모델 (Uber EATS ETD)
UberEATS는 음식 배달 시간 예측, 검색 랭킹, 검색 자동완성, 음식점 랭킹등을 포함하여, Michelangelo 에서 실행되는 여러가지 모델이 있습니다. 배달 시간 모델은 주문이 들어가기 전과 배달의 각 단계에서 음식이 준비되고 배달되기까지 얼마의 시간이 걸리는지 예측합니다.
 Figure 1: UberEATS 앱은 Michelangelo에서 만들어진 머신러닝 모델을 이용하여 배달 시간을 예측합니다.
Figure 1: UberEATS 앱은 Michelangelo에서 만들어진 머신러닝 모델을 이용하여 배달 시간을 예측합니다.
음식 배달 시간을 예측하는 것은 쉬운일이 아닙니다. UberEATS의 사용자가 주문할 때 주문 요청을 처리하기 위해 음식점에 주문이 보내집니다. 음식점은 주문에 대해 응답하고 음식을 준비해야하는데, 주문의 복잡성과 음식점이 얼마나 바쁜지에 따라 얼마의 시간이 걸릴지 결정됩니다. 음식이 거의 준비되었을 때, Uber의 배달원이 음식을 픽업하도록 배정됩니다. 그리고 배달원은 음식점에 방문하고, 주차할 장소를 찾고, 음식점 안에 들어가서 음식을 받은 후, 차에 돌아와서 주문한 사람의 위치로 이동하고(이동경로, 트래픽, 기타 등등 의 영향을 받습니다), 주차공간을 찾고, 주문자의 문 앞에 가서 배달을 완료합니다. 그래서 Uber에서는 이러한 복잡한 여러 단계에 대해 전체 소요시간을 예측하는 것은 물론 각 단계에서 배달에 걸리는 시간을 재계산하는 것까지를 목표로 하고 있습니다.
UberEATS의 데이터사이언티스트들은 Michelangelo 플랫폼에서 이 end-to-end 배달 시간을 예측하는데, gradient boosted decision tree regression 모델을 사용합니다. 모델의 feature들은 주문 요청 (요청시간, 배달 장소 등) 에 대한 정보, historical feature들 (예를 들어 최근 7일간의 평균 음식 준비 시간), 그리고 near-realtime에 계산되는 feature들 (예를 들어, 지난 한 시간 동안의 평균 음식 준비 시간)을 포함합니다. 모델들은 Uber의 데이터센터를 지나 Michelangelo 모델 서빙 컨테이너로 배포되고, UberEATS의 마이크로 서비스들의 네트워크 요청에 의해 호출됩니다. 이러한 예측들은 UberEATS의 고객에게 음식점에서 주문하기 전, 그리고 음식이 준비되고 배달되는 동안에 디스플레이됩니다.
System architecture
Michelangelo 는 오픈소스 시스템들과 built in-house 컴포넌트들의 조합으로 구성되어 있습니다. 주요한 오픈소스 컴포넌트들로는 HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, Tensorflow 를 사용하고 있습니다. 우리는 일반적으로 가능하면 fork하고, 커스터마이즈하고, 필요하다면 contribute 할 수 있는 성숙한 오픈소스 옵션을 사용하는 것을 선호하고, 오픈소스 솔루션이 우리의 usecase에 맞지 않으면 종종 우리 스스로 시스템을 구축합니다.
Michelangelo는 Uber의 데이터와 계산 인프라의 최상단에 구축되어, Uber의 내역과 로깅된 데이터를 저장하고 있는 data lake, 모든 Uber의 서비스들에서 로깅된 메시지들을 모으는 Kafka 브로커, Samza streaming 계산 엔진, Cassandra 클러스터, 그리고 Uber의 프로비저닝된 in-house 서비스, 그리고 배포 툴을 제공하고 있습니다.
다음 section에서는, Michelangelo의 기술 세부사항에 대해 설명하기 위해 UberEATS ETD 모델을 case study로 하여 시스템 레이어를 살펴보겠습니다.
Machine Learning Work Flow
분류, 회귀, 시계열 예측을 포함하여 Uber의 대부분의 머신러닝 usecase들은 대부분 같은 workflow를 따릅니다. Workflow는 일반적으로 구현에 독립적이고, 새로운 딥러닝 framework들과 같이 새로운 알고리즘 타입과 framework를 지원하기 위해 쉽게 확장됩니다. 그리고 online, offline (차안 그리고 휴대폰)에서의 예측 사례들과 같이 서로 다른 배포 모드들에도 적용됩니다.
우리는 다음 여섯 단계의 workflow를 따르기 위해 Michelangelo를 확장성있고, 안정성있고, 재생산가능하고, 사용하기 쉽고, 자동화된 기능을 제공하도록 설계했습니다.
- Manage data
- Train models
- Evaluate models
- Deploy models
- Make predictions
- Monitor predictions
그리고, 우리는 Michelangelo의 아키텍쳐가 어떻게 이 workflow의 각 단계를 용이하게 하도록 하는지 세부적으로 보려고 합니다.
Manage data
우리는 좋은 feature를 찾는 것은 종종 머신러닝에서 가장 어려운 부분이고, 데이터 파이프라인을 구축하고 관리하는 것은 완전한 머신러닝 솔루션에서 가장 비용이 많이 드는 부분 중의 하나라는 사실을 발견했습니다.
학습(그리고 재학습)을 위한 feature와 정답 데이터셋과 예측을 위한 feature로만 구성된 데이터 셋 생성을 위한 데이터파이프라인을 구축하기 위해 머신러닝 플랫폼을 표준화된 도구들을 제공해야합니다. 이러한 도구들은 회사의 data lake 또는 ware house, 회사의 실시간 데이터 제공 시스템들과 깊이 통합되어 있어야합니다. 파이프라인들은 확장성 있고 효율적이어야하며, 데이터 흐름과 질에 대한 통합된 모니터링을 포함해야하고, online과 offline 학습과 예측을 지원해야합니다. 이상적으로 파이프라인들은 중복된 작업을 줄이고 데이터의 질을 높이기 위해서, 여러 팀들이 공유가능한 형태로 feature들을 생성해야합니다. 또한 사용자들로 하여금 best pratices들(예를 들어, 학습과 예측 단계에서 같은 데이터 생성 및 전처리 과정을 거치도록 하는 것을 쉽게 보장 하는 것)을 적용하기 용이하도록 하기 위해 강력한 가드레일과 제어 기능을 제공해야합니다.
Michelangelo의 데이터 관리 구성요소들은 online과 offline 파이프라인으로 나뉘어집니다. 최근에, offline 파이프라인들은 배치 모델을 학습하고, 예측하는 작업들에 사용되고, online 파이프라인들은 online 학습과 low latency를 가지는 예측들에 사용됩니다.
또한, 사내 팀들이 그들의 머신러닝 문제에 대해 서로 공유하고, 발견하고, 잘 선정된 feature셋을 사용 할 수 있도록 데이터 관리 계층에 feature저장소를 추가 했습니다. 우리는 Uber의 많은 모델링 문제들이 동일하거나 비슷한 feature들을 사용한다는 것과, 이것이 사내 서로 다른 조직의 팀들에게 서로의 feature를 공유하는 것이 가능하다는 점에 상당한 가치가 있다는 것을 발견했습니다.
 Figure 2: 데이터 준비 파이프라인에서 데이터를 Featrue Store 테이블과 학습 데이터 저장소에 넣습니다.
Figure 2: 데이터 준비 파이프라인에서 데이터를 Featrue Store 테이블과 학습 데이터 저장소에 넣습니다.
Offline
Uber의 거래 내역과 로그 데이터는 HDFS data lake로 흘러들어가고, Spark와 Hive SQL 계산 job으로 쉽게 접근가능합니다. 우리는 프로젝트에 private 하거나 팀들간에서 공유할 수 있도록 Feature Store에 배포되는 feature들을 계산하기 위한 규칙적인 job을 돌리기 위해 컨테이너와 스케줄링을 제공합니다. 배치 job들은 스케줄러 또는 트리거에 의해 동작하고, 코드나 데이터 이슈들 에서 발생한 이상현상을 빠르게 탐지하기 위해 data quality 모니터링 툴로 통합됩니다.
Online
온라인에 배포된 모델들은 HDFS에 저장된 데이터에 접근할 수 없고, 종종 성능 관점에서 직접 Uber의 production 서비스의 온라인 database로 부터 계산하기 어려운 feature들이 있습니다. (예를 들어, 특정 기간대의 한 음식점의 평균 음식 준비 시간을 계산하기 위해 UberEATS의 주문 서비스 database에 직접 query할 수 없습니다.) 그래서, 우리는 온라인 모델에 필요한 feature들을 예측이 필요한 시점에 low latency로 읽을 수 있는 Cassandra애 미리 계산해서 저장해두었습니다.
우리는 온라인에서 서비스되는 feature들을 계산하기 위해 두가지 옵션(아래 batch 계산, near-real-time 계산 방식)을 제공합니다.
Batch precompute. 첫 번째 옵션은 bulk 선행 계산과 HDFS에서 Cassandra로 historical feature들을 불러오는 옵션입니다. 이 일은 간단하면서 효율적이고, 일반적으로 매 시간이나 하루마다 갱신되는 historical feature에 잘 동작합니다. 이 시스템은 같은 데이터와 batch 파이프라인을 학습과 serving에 사용한다는 것을 보장합니다. UberEATS는 이 시스템을 ‘특정 음식점의 최근 7일간의 평균 음식 준비 시간’과 같은 feature들에 사용합니다.
Near-real-time compute. 두 번째 옵션은 관련있는 metric들을 Kafka에 배포하고, low latency로 aggregation feature들을 만들기 위해 Samza 기반의 스트리밍 계산 job을 돌리는 것입니다. 이러한 feature들은 serving을 위해 Cassandra에 바로 쓰여지고, 미래의 학습 job을 위해 HDFS에 로그로 남습니다. 배치 시스템과 같이 near-real-time 계산 또한 같은 데이터와 batch 파이프라인을 학습과 serving에 사용한다는 것을 보장합니다. 우리는 데이터를 다시 채우기 위해 로그 데이터에 맞게 배치 잡을 돌려서 학습 데이터를 생성합니다. UberEATS는 near-realtime 파이프라인을 ‘특정 음식점의 지난 1시간 동안의 평균 음식 준비 시간’ 와 같은 feature들에 사용합니다.
Shared feature store
우리는 Uber의 팀들이 자신들의 팀 또는 다른 팀에서 사용되는 공동의 feature들을 만들고 관리할 수 있는 중앙화된 Feature Store를 만드는 것이 큰 가치가 있다는 사실을 발견했습니다. 높은 관점에서 이것은 두 가지를 달성했습니다.
이것은 프로젝트의 목적을 위해 사용자들이 만든 feature들을 공유된 feature store에 쉽게 추가할 수 있도록 합니다. 한번 feature들이 Feature Store에 저장되면, feature의 정규 이름을 참조하는 방식으로 online과 offline 모두에서 사용하기 매우 쉬워집니다. 이러한 정보를 장착하고, 이 시스템은 모델 학습이나 배치 예측에 필요한 정확한 HDFS 데이터셋들을 join하고, online 예측을 위해 Cassandra에서 정확한 값을 가져오는 것을 핸들링합니다.
현재, 우리는 Feature Store에 머신러닝 프로젝트들을 가속화 하기 위해 사용되는 대략 10,000개의 feature를 저장하고 있습니다. 그리고 회사내 팀들은 동시에 새로운 feature들을 추가하고 있습니다. Feature Store에 저장된 feature들은 일별로 자동으로 계산되고 갱신됩니다.
앞으로는, 우리는 주어진 예측 문제를 해결하기 위해 Feature Store를 검색하여 가장 유용하고 중요한 feature들을 식별하는 자동화된 시스템을 만들 수 있는 가능성을 찾을 계획입니다.
Domain specific language for feature selection and transformation
데이터 파이프라인에서 생성되거나, 클라이언트 서비스에서 보내진 feature들은 종종 모델에 적합한 형식을 가지고 있지 않고 또는, 값을 채워야하는 결측값일 수 있습니다. 더욱이 모델이 주어진 feature들의 부분 집합만을 필요로 할수도 있습니다. 예를들어, timestamp를 하루 중의 시간 또는 요일로 변경하는 것이 주기적 패턴을 찾는 모델에 더 유용할 수 있습니다. 다른 케이스로는, feature 값들이 정규화될 필요가 있습니다. (평균과 표준편차를 구하는 등)
이러한 문제들을 풀기위해, 우리는 모델러들이 모델을 학습하고 예측하는 시점에 모델에 보내지는 feature들을 선택하고, 변형하고, 결합할 수 있는 DSL (domain specific language)를 만들었습니다. DSL은 Scala의 부분 집합으로 구현되었습니다. 이것은 일반적으로 많이 사용되는 함수들의 완전한 집합을 가진 순수 함수형 언어입니다. DSL을 이용해서 우리는 또한 고객팀이 그들만이 고유하게 정의한 함수들을 추가할 수 있는 가용성을 제공합니다. 그리고 현재의 context (데이터 파이프라인)에서 feature값들을 가져오는 accessor하는 함수가 있습니다.
DSL 표현식들은 모델 구성의 한 부분이고, 같은 최종 feature 세트를 보장하기 위해 같은 표현식들이 학습 시점과 예측시점에 적용된다는 사실은 중요합니다.
Train models
우리는 최근에 offline 상에서 큰 스케일로 분산 처리되는 Decision tree 학습, linear와 logistic 모델들, unsupervised 모델들 (k-means), 시계열 모델들, 딥러닝을 지원합니다. 우리는 고객의 필요에 대한 대응으로 규칙적으로 Uber의 AI lab이나 내부 연구자들이 개발한 새로운 알고리즘들을 추가합니다. 또한 우리는 커스텀 학습, evaluation과 serving 코드를 제공하여 사내 팀들이 그들만의 모델 타입을 추가할 수 있도록 합니다. 분산 모델 학습 시스템은 수 억개의 샘플들을 다루기 위해 확장되고, 빠른 반복을 위한 작은 데이터셋까지 스케일 다운 됩니다.
모델 configuration은 모델 타입, hyper parameter, 데이터 소스, feature DSL 표현식들 뿐 아니라, 컴퓨팅 리소스 요구사항들(머신 수, 메모리량, GPU 사용여부 등)까지 명시합니다. 이 명세는 YARN이나 Mesos 클러스터에서 돌아가는 학습 job을 구성하는데 사용됩니다.
모델이 학습되고 난 후, 성능 지표(예: ROC 곡선, PR 곡선)들이 계산되어 모델 평가 보고서에 결합됩니다. 학습이 끝나고 원래의 configuration과 학습된 parameter들, 평가 보고서들은 분석과 배포를 위해 우리의 모델 저장소에 저장됩니다.
단일 모델을 학습하는 것 외에도, Michelangelo는 파티션된 모델을 포함해서 모든 타입의 모델에 대해 hyper-parameter 검색을 지원합니다. 파티션된 모델을 사용하여 우리는 자동으로 사용자의 configuration에 따라 학습 데이터를 분할하고, 파티션 별로 모델을 학습하고 필요할 때 상위 모델로 되돌립니다 (예: 도시 별로 모델을 학습시키고, 정확한 도시 수준의 모델을 얻을 수 없을 때 국가 수준의 모델로 되돌립니다.).
학습 job들은 웹 UI나 API, 또는 종종 Jupyter notebook을 통해 관리되고 구성될 수 있습니다. 많은 팀들은 API와 workflow 도구를 사용하여 정기적으로 모델을 재학습합니다.
 Figure 3: 모델 학습 작업들은 Feature Store와 학습 데이터 저장소의 데이터셋을 사용하여 모델을 학습하고, 모델 저장소에 저장합니다.
Figure 3: 모델 학습 작업들은 Feature Store와 학습 데이터 저장소의 데이터셋을 사용하여 모델을 학습하고, 모델 저장소에 저장합니다.
Evaluate models
모델들은 주로 문제를 해결에 가장 좋은 모델을 생성하는 feature 집합, 알고리즘, hyper-parameter들을 식별하기 위한 체계적인 탐색 프로세스의 일부로 학습됩니다. 주어진 usecase에 이상적인 모델에 도달하기 전에 목표를 달성하지 못하는 수 백개의 모델을 학습하는 일은 드문 일이 아닙니다. 비록 최종적으로 제품에 사용되지 않지만, 이러한 모델들의 성능은 엔지니어들이 가장 좋은 모델에 대해 configuration을 할 수 있도록 가이드 해줍니다. 이러한 학습된 모델들을 지속적으로 트래킹(예: 누가 그 모델들은 언제 어떤 데이터셋과 hyper-parameter로 학습했는지 등) 하고, 평가하고, 다른 모델들과 비교하는 것은 수많은 모델들을 다루는 환경에서 일반적으로 큰 어려움이 있고, 현재 플랫폼에는 큰 가치를 더할 수 있는 기회입니다.
Michelangelo에서 학습된 모든 모델들에 대한 버전 객체를 우리의 Cassandra의 모델 저장소에 저장합니다. 버전 객체는 다음의 내용을 포함하고 있습니다.
- 누가 모델을 훈련 시켰는가?
- 학습 작업의 시작 및 종료 시간
- 전체 모델 구성 (사용된 feature들, hyper-parameter 값 등)
- 학습 및 테스트 데이터셋에 대한 참조
- 각 feature들의 분포와 중요도
- 모델 정확도 지표
- 각 모델 타입에 대한 표준 차트와 그래프 (예: 이진 분류기에 대한 ROC 곡선, PR 곡선, confusion matrix)
- 모델에서 학습된 전체 paramter들
- 모델 시각화를 위한 요약 통계
이러한 정보는 웹 UI를 통해 사용자들이 쉽게 사용할 수 있고, API를 통해 개별 모델들의 세부 사항에 대한 검사와 하나 이상의 서로 다른 모델들을 비교할 수 있습니다.
Model accuracy report
회귀 모델에 대한 모델 정확성 보고서는 표준 정확도 지표와 차트들을 보여줍니다. 분류 모델들은 Figure 4나 5와 같이 다른 집합을 표시합니다:
 Figure 4: Regression 모델 리포트는 regression과 연관된 성능 지표를 보여줍니다.
Figure 4: Regression 모델 리포트는 regression과 연관된 성능 지표를 보여줍니다.
 Figure 5: 이진 분류의 성능 리포트는 분류와 연관된 성능 지표를 보여줍니다.
Figure 5: 이진 분류의 성능 리포트는 분류와 연관된 성능 지표를 보여줍니다.
Decision tree visualization
중요한 모델 타입의 경우, 우리는 모델러들이 왜 모델이 정상적으로 작동하는지 이해하고 필요한 경우 디버깅할 수 있도록 돕기 위해 정교한 시각화 도구들을 제공합니다. Decision tree 모델들의 경우, 우리는 사용자들이 각각의 개별 tree들을 탐색하여 전체적인 모델에 대한 상대적인 중요도, 분할 지점, 특정 tree에 대한 개별 feature들의 중요도, 각 분할 지점에서의 데이터 분포를 확인할 수 있게 합니다. 아래 Figure 6에서 보듯이, 사용자가 feature 값을 명시할 수 있고, 그에 따라 decision tree에서 활성화되는 경로, tree 별 예측, 전체적인 모델의 예측에 대해 시각화합니다:
 Figure 6: Tree 모델들은 강력한 tree 시각화로 탐색할 수 있습니다.
Figure 6: Tree 모델들은 강력한 tree 시각화로 탐색할 수 있습니다.
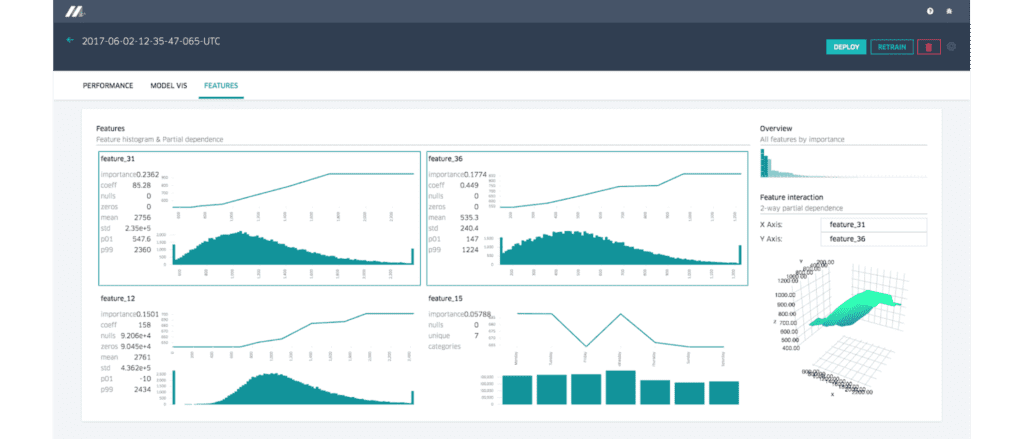
Feature report
Michelangelo는 개별 feature들에 대해 모델에서의 중요도 순으로 부분적 의존 관계 그래프와 분포 histogram을 보여주는 feature 보고서를 제공합니다. 아래와 같이, 두 가지 feature를 선택하면 사용자는 양방향 부분적 의존 관계 다이어그램을 통해 feature들의 상호작용에 대해 이해할 수 있습니다:
 Figure 7: Feature들, 모델에서의 영향력, feature 간 상호작용을 탐색해 볼 수 있습니다.
Figure 7: Feature들, 모델에서의 영향력, feature 간 상호작용을 탐색해 볼 수 있습니다.
Deploy models
Michelangelo는 UI 또는 API를 통해 모델 배포 관리를 위한 end-to-end 지원을 제공하고, 모델을 배포할 수 있는 세 가지 모드를 지원합니다:
Offline deployment. 이 모델은 offline 컨테이너에 배포되고, on demand 또는 반복되는 스케줄링에 따른 배치 예측 작업을 위해 Spark job에서 실행됩니다.
Online deployment. 이 모델은 online 예측 서비스 클러스터(일반적으로 load balancer 뒤에 수 백개의 머신을 포함하고 있는)에 배포됩니다. Client는 RPC 호출과 같은 개별 또는 배치 예측 요청을 보낼 수 있습니다.
Library deployment. 우리는 다른 서비스에서 라이브러리 형태로 내재화되어 Java API로 호출될 수 있는 모델을 serving 컨테이너에 배포하려고 합니다. (아래 Figure 8에는 표시되어 있지 않지만 online deployment와 유사하게 동작합니다)
 Figure 8: 모델 서빙을 위해 모델 저장소로부터 모델이 online과 offline 컨테이너에 배포됩니다.
Figure 8: 모델 서빙을 위해 모델 저장소로부터 모델이 online과 offline 컨테이너에 배포됩니다.
모든 케이스에서, 배포에 필요한 모델 결과물(metadata 파일, 모델 parameter 파일, 컴파일된 DSL 표현식들)은 ZIP 파일로 압축되고, 우리의 표준 코드 배포 인프라를 사용하여 Uber의 데이터 센터를 통해 연관있는 host에게로 복사됩니다. 예측 컨테이너들은 자동적으로 디스크로부터 새로운 모델을 불러오고 예측 요청을 처리하기 시작합니다.
많은 팀들은 Michelangelo의 API를 활용하여 주기적인 모델 재학습과 배포를 위한 자동 스크립트를 보유하고 있습니다. UberEATS의 배달 시간 모델의 사례에서는, 데이터사이언티스트들과 엔지니어들이 웹 UI를 통해 학습과 배포를 수동으로 트리거 합니다.
Make predictions
한번 모델이 배포되고 서빙 컨테이너에 로드되면, 모델들은 데이터 파이프라인이나 client 서비스로 부터 직접 불러온 feature 데이터를 기반으로 예측 작업을하는 데 사용됩니다. 원본 feature들은 원본 feature를 수정하거나, Feature Store에서 부가적인 feature를 추가할 수 있는 컴파일된 DSL 표현식에 전달됩니다. 그리고 최종 feature vector가 계산되어 스코어링을 위해 모델에 전달됩니다. Online 모델의 경우, 예측 결과는 네트워크를 통해 Client 서비스에 반환됩니다. Offline 모델의 경우, 예측 결과는 Hive에 다시 쓰여지고, 배치 작업에 사용되거나 사용자가 SQL 기반 쿼리 툴을 사용해서 접근할 수 있습니다.
 Figure 9: Online과 Offline 예측 서비스에서 feature vector 셋을 예측하는데 사용합니다.
Figure 9: Online과 Offline 예측 서비스에서 feature vector 셋을 예측하는데 사용합니다.
Referencing models
하나 이상의 모델을 주어진 서빙 컨테이너에 동시에 배포할 수 있습니다. 이것은 이전 모델을 새로운 모델로 안전하게 변경하는 작업과 모델 간 A/B테스팅을 가능하게 합니다. 서빙 시점에서, UUID와 배포중에 명시된 부가적인 태그(또는 별칭)를 통해 모델이 식별됩니다. Online 모델의 경우, 클라이언트 서비스가 사용하고자 하는 모델의 UUID나 모델 태그와 함께 feature vector를 전송합니다. 태그를 사용할 경우, 컨테이너는 해당 태그에 가장 최근에 배포된 모델을 사용하여 예측 결과를 생성합니다. 배치 모델의 경우 모든 배포된 모델들은 개별 배치 데이터셋에 대해 점수를 매기는데 사용되고, 예측 결과들이 모델 UUID와 부가적인 태그를 포함하고 있어 사용자가 적절하게 결과를 필터링할 수 있습니다.
만약 이전 모델을 대체하기 위해 새로운 모델을 배포할 때 두 모델이 같은 signature를 가졌다면(예: 동일한 feature 셋을 가졌을 경우), 사용자들은 새로운 모델을 이전 모델과 같은 태그로 배포할 수 있고, 컨테이너들은 새로운 모델을 즉시 사용하기 시작합니다. 이것은 사용자들이 그들의 client 코드를 수정하지 않고도 모델을 갱신할 수 있게 해줍니다. 사용자들은 또한 이전 모델에서 새로운 모델로 점진적으로 트래픽을 전환하기 위해 client나 중간 서비스에서 UUID만으로 새로운 모델을 배포하고 configuration을 변경할 수 있습니다.
모델 간의 A/B 테스팅을 위해, 사용자들은 간단하게 UUID나 태그를 통해 비교할 모델들을 배포할 수 있고, 클라이언트 서비스에서 Uber의 실험 프레임워크를 사용하여 트래픽의 일부를 각 모델에 보내고 성능 지표를 트래킹할 수 있습니다.
Monitor predictions
모델이 학습되고 평가될 때, 기록 데이터가 항상 사용됩니다. 특정 모델이 미래에도 잘 동작할 지 확인하기 위해, 데이터 파이프라인이 계속 정확한 데이터를 전송하고 모델이 더 이상 정확하지 않게 production 환경이 변하지 않았는지 모델의 예측 결과를 모니터링 하는 것은 중요합니다.
이 문제를 해결하기 위해 Michelangelo는 자동으로 로그를 기록하고, 선택적으로 예측 결과 비율을 저장하여 데이터 파이프라인에서 생성된 실제 관측 결과(또는 label)와 결합합니다. 이러한 정보를 통해 우리는 실시간으로 모델의 정확도에 대한 지표를 생성할 수 있습니다. 회귀 모델의 경우, 아래 그림과 같이 우리는 예측 결과에 대한 R-squared/coefficient, root mean square logarithmic error (RMSLE), root mean square error (RMSE), mean absolute error 지표를 Uber의 시계열 모니터링 시스템에 발송하여 사용자들이 시간에 따라 차트를 분석하고 특정 threshold 값으로 알람을 설정할 수 있도록 합니다.
 Figure 10: 예측 결과가 샘플링되고 관측 결과와 비교하여 모델의 정확도 지표를 생성합니다.
Figure 10: 예측 결과가 샘플링되고 관측 결과와 비교하여 모델의 정확도 지표를 생성합니다.
Building on the Michelangelo platform
앞으로 몇 달 동안, 우리는 고객 팀과 Uber 비즈니스 전반의 성장을 지원하기 위해 기존 시스템을 아래와 같은 기능들에 대해 계속 확장하고 강화할 계획입니다. 플랫폼 계층이 성숙 해짐에 따라 우리는 머신러닝의 민주화를 추진하고 비즈니스 요구를 보다 잘 지원하기 위해 더 높은 수준의 도구와 서비스에 투자 할 계획입니다.
AutoML. 이것은 주어진 모델링 문제에서 모델이 최고의 성능을 내도록 하는 configuration(알고리즘, feature 셋, hyper-parameter 값들 등)들을 자동적으로 검색하고 발견하는 시스템이 될 것 입니다. 이 시스템은 또한 모델에 필요한 feature들과 label들을 생성하기 위해 자동적으로 production 데이터 파이프라인들을 생성할 것 입니다. 우리는 우리의 Feature Store, 균일화된 오프라인과 온라인 데이터 파이프라인들, hyper-parameter 검색으로 이 문제에 대한 큰 부분들을 이미 해결했습니다. 우리는 초반의 데이터 사이언스 업무를 AutoML을 통해 가속화하려고 합니다. 이 시스템은 데이터 과학자들이 label들과 목적함수를 정의하고, Uber의 데이터를 보안적으로 안전하게 사용하여 문제에 대한 최적을 답을 찾을 수 있도록 합니다. 목표는 똑똑한 도구로 데이터 과학자들을 일을 손쉽게 만들어서 생산성을 높이는 것입니다.
Model visualization. 모델을 이해하고 디버깅하는 것은 특히 딥러닝에서 점점 중요해지고 있습니다. 우리가 트리 기반의 모델들을 시각화하는 도구로 몇가지 중요한 첫 스텝들을 밟고 있는 반면, 데이터 과학자들이 예측 결과를 믿고, 모델을 이해하고, 디버그하고 튜닝하기 위해 완료되어야 할 더 많은 니즈들이 남았습니다.
Online learning. 대부분의 Uber의 머신러닝 모델들은 직접적으로 Uber의 production 환경에 실시간으로 영향을 끼칩니다. 이것은 그들이 물리적 세계의 물체가 움직이는, 복잡하고 계속 변화하는 환경에서 동작을 실행한다는 의미입니다. 우리의 모델이 환경이 변화하더라도 정확성을 유지하기 위해, 우리는 변화에 맞게 모델을 변경해야합니다. 현재, 팀들은 규칙적으로 Michelangelo에서 그들의 모델을 재학습시킵니다. 이 use case에 대한 완벽한 플랫폼 솔루션은 손쉬운 모델 타입 갱신, 빠른 학습과 평가 구조 및 파이프라인, 자동화된 모델 검증 및 배포 그리고 섬세한 모니터링과 알림 시스템을 포함합니다. 큰 프로젝트일지라도, 초기 결과물은 online learning을 당장 시작하는 것이 뒤따라오는 잠재적인 이익을 얻을 수 있음을 나타냅니다.
Distributed deep learning. 증가하고 있는 Uber의 머신러닝 시스템들은 딥러닝 기술로 구현되어있습니다. 딥러닝 모델을 정의하고 반복시키는 사용자의 워크플로는 표준화된 워크플로와 충분히 달라 플랫폼의 고유한 지원이 필요합니다. 딥러닝 use case들은 일반적으로 많은 양의 데이터를 다루고, GPU같은 다른 하드웨어 사양이 필요하기때문에, 분산 학습에 대한 더 많은 투자와 유연한 자원관리 스택과 긴밀한 통합을 유도하고 있습니다.