본 포스트의 원문은 아래의 링크에서 보실 수 있습니다.
또한 원문 포스트는 2018.07.21 에 작성되었던 점을 감안하고 봐주세요~!
이 글은 다양한 자연어 처리 및 자연어 이해 문제를 풀기 위해 기계 학습 및 딥러닝 기술의 적용 사례를 다루는 우리 회사의 iki 프로젝트와 관련 있는 일련의 기술 게시물 중 첫 번째 기사입니다.
이 포스트에서 우리는 구조화되지 않은 텍스트로부터 특정 정보를 추출하는 문제에 대해 대처할 것입니다. 우리는 우리 사용자들의 전물기술들(Skills) 을 그들의 이력서(Curriculum Vitae, CV) 로 부터 추출할 필요가 있었습니다. 심지어 사용자들이 이력서에 ‘양적 거래 알고리즘을 프로덕션 서버에 배포 ’ 와 같은 임의의 방식으로 작성한 경우에도 적용할 수 있도록 해야했습니다.
이 포스트는 데모 페이지가 있습니다. 우리의 모델의 성능을 당신의 이력서를 통해 확인해보세요.
언어 모델 (Linguistic Models)
최근의 언어모델들(ULMfit, ELMo) 은 특정 지도학습 훈련 단계 전에 언어 구조에 대한 일부 원시 지식을 얻기 위해 대형 텍스트 코퍼스에 RNN 임베딩을 생성하는 것과 같은 비지도학습 기술을 사용합니다[1]. 하지만 어떤 경우에 당신은 구체적이고 작은 데이터셋에 대해 학습된 모델이 필요합니다[2]. 이 모델은 일반적인 언어 구조에 대해서는 거의 지식을 갖고 있지 않으며 특수한 텍스트 feature로만 동작합니다. 고전적인 예로 영화 리뷰 또는 뉴스 데이터셋에 대해 나이브한 감정 분석 툴을 사용하는 것이 있을 것입니다.
Naive Sentiment Analysis tool은 ‘좋음’, ‘나쁨’의 형용사 동의어와 문서 내의 일부 단어의 존재를 강조하는 경우에만 작동할 수 있습니다.
우리의 연구에서는 [1], [2] 두 가지 접근법의 장점들을 취하려고 했습니다.
일반적으로 텍스트 코퍼스를 분석할 때 우리는 각 텍스트의 전체 어휘를 보고 있습니다. ~과 같은 텍스트를 벡터화 하는데 인기 있는 방법들은 벡터를 생성하기 위해 Stopwords를 제외한 전체 문서의 어휘를 사용합니다.
Stopwords : 관사, 대명사 및 이와 유사한 언어 요소로 통계적 평균 절차에서 의미를 거의 갖지 않는 매우 일반적인 언어 요소
구체적인 작업이 있고 텍스트 코퍼스에 대한 몇 가지 추가 정보가 있는 경우엔 일부 정보가 다른 정보보다 더 가치가 있다고 말할 수 있습니다. 예를 들어 레시피 코퍼스에 대한 분석을 수행하려면 텍스트에서 재료 또는 요리 이름 클래스를 추출하는 것이 중요합니다. 또 다른 경우는 아래의 예시처럼 이력서 코퍼스에서 ‘전문기술’ 클래스를 추출하는 것입니다. 추출 된 ‘전문기술’의 벡터와 연관시켜 각 이력서를 벡터화할 수 있다면 훨씬 더 성공적인 산업 포지션 클러스터링을 수행할 수 있습니다.
1단계 : 품사 태깅 (Parts of speech tagging)
개체(Entity) 추출 작업은 텍스트 마이닝의 클래스 문제의 일부로 구조화되지 않은 비정형의 텍스트에서 일부 구조화 된 정보를 추출하는 작업입니다. 기존에 제안됐던 개체 추출 방법을 자세히 살펴보겠습니다. 이력서에서의 ‘전문기술’이 소위 명사구에 주로 존재하는한 이 ‘전문기술’을 추출하는 과정의 첫 번째 단계는 개체 인식을 하는 것입니다. 우리는 이를 위해 NLTK 라이브러리의 내장 메소드를 사용했습니다 (자세한 사항은 NLTK book, part7 - Extracting Information from Text 부분을 살펴보세요). 품사 태깅 방법은 명사구(Noun Phrases, NP)를 추출하고 명사구와 문장의 다른 부분들 사이의 관계를 나타내는 트리를 만듭니다. NLTK 라이브러리에는 이러한 구문 분해를 수행하는 많은 툴들이 있습니다.
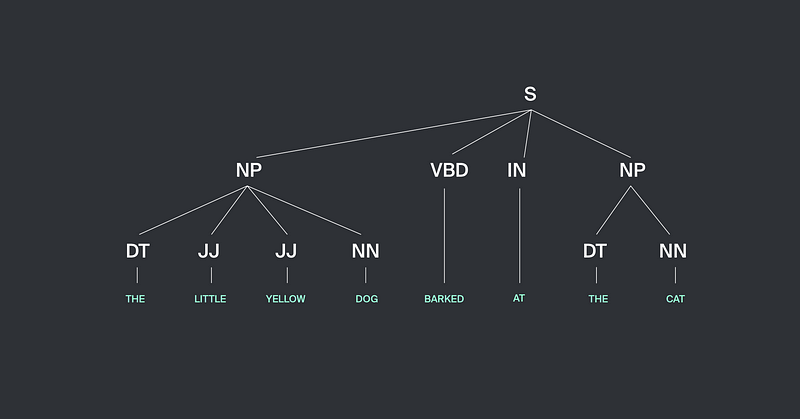
우리는 모델을 문장 분해를 제공하는 정규 표현식으로써 정의할 수 있습니다 (예를 들어, 여러 형용사와 명사의 조합으로 구를 정의할 수 있습니다) 또는 우리는 NLTK에 내장되어 있는 이미 추출된 명사구 예제를 사용하여 레이블링을 한 많은 텍스트를 통해 우리의 모델을 학습시킬 수 있습니다. 이 단계에서는 우리가 추출하고자 하는 대상인 ‘전문기술’과 더불어 다수의 대상이 아닌 일반적인 개체들(장소, 사람, 물건, 조직 등)이 포함될 수 있습니다.
2단계 : 후보군 분류(Candidates Classification) 를 위한 딥러닝 아키텍쳐
첫 번째 단계로 품사 태깅을 통해 개체 인식을 완료했다면, 다음 단계는 개체를 분류하는 것입니다. 여기서 우리의 목적은 ‘전문기술’이 아닌 것들 사이에 섞여 있는 ‘전문기술’을 찾아내는 것입니다. 모델 훈련을 위해 사용된 feature 들의 집합은 후보 구문의 구조와 관련 있게 구성됩니다. 분명히 모델을 훈련시키기 위해 우리는 래이블링이 된 훈련 세트를 생성할 필요가 있었습니다. 우리는 이것을 위해 직접 ‘전문기술’과 ‘전문기술’이 아닌 개체들이 포함되어있는 1500개의 이미 추출된 개체들을 가지고 레이블링을 진행했습니다.
우리는 모델을 하드 코딩된 ‘전문기술’들 세트에 맞추려고 시도하지 않았습니다. 우리 모델의 핵심 아이디어는 영어 이력서에서 ‘전문기술’의 의미를 배우고 보이지 않는 ‘전문기술’들을 추출하기 위해 모델을 사용하는 것입니다.
각각의 단어들에 대한 벡터는 숫자 또는 특수 문자 포함 여부, 첫 문자 또는 전체 문자가 대문자인지 여부에 대한 binary feature들로 구성되어 있습니다.
‘전문기술’을 의미하는 단어는 숫자 또는 기타 특수 단어를 포함하는 경우가 많고, 첫 문자만 대문자이거나 전체 문자가 대문자로 쓰여진 경우가 있기 때문에 이에 대한 정보를 주기 위해 binary feature를 추가했습니다. (예를 들어 C#, Python3, SQL)
또한 자주 쓰이는 영어 접두사 및 접미사의 존재 여부를 설명하는 다른 binary feature 를 사용한 것은 테스트 셋에서 성능을 77.3 % 까지 개선시켰습니다. 추가적으로 품사 태깅에 대한 원-핫 벡터 인코딩을 모델의 feature 셋에 추가한 것은 우리의 결과를 84.6% 까지 빠르게 끌어올렸습니다.
신뢰할만한 시맨틱 단어 임베딩 모델은 이력서 데이터셋에서는 훈련되기 어렵습니다. 그 이유는 이력서 데이터셋은 크기가 작고 스펙트럼이 좁기 때문에 다른 대규모의 데이터셋을 통해 훈련된 단어 임베딩을 사용해야만 이 문제를 완화할 수 있습니다. 우리는 50차원의 GloVe 모델 벡터를 사용하여 모델의 성능을 테스트셋에서 최대 89.1%의 정확도를 달성할 수 있었습니다. 여러분은 우리의 최종 모델을 데모 페이지에서 본인의 이력서를 업로딩하는 것을 통해 확인해볼 수 있습니다.

인기 있는 품사 태거들(NLTK POS tagger, Stanford POS tagger) 은 종종 이력서의 구문을 태깅하는 작업에서 실수를 범하곤 합니다. 그 이유는 종종 이력서의 텍스트가 경험을 강조하고 어떤 구조를 부여하기 위해 문법을 무시하기 때문입니다 (주어가 아닌 술어로 문장을 시작하거나 때로는 적절한 문법 구조를 피하는 경우). 그리고 이력서에 사용되는 단어는 전문 용어이거나 이름인 경우가 많습니다. 그 때문에 앞서 말한 문제들을 해결하기 위해 우리는 자체 품사 태거를 만들어야 했습니다.
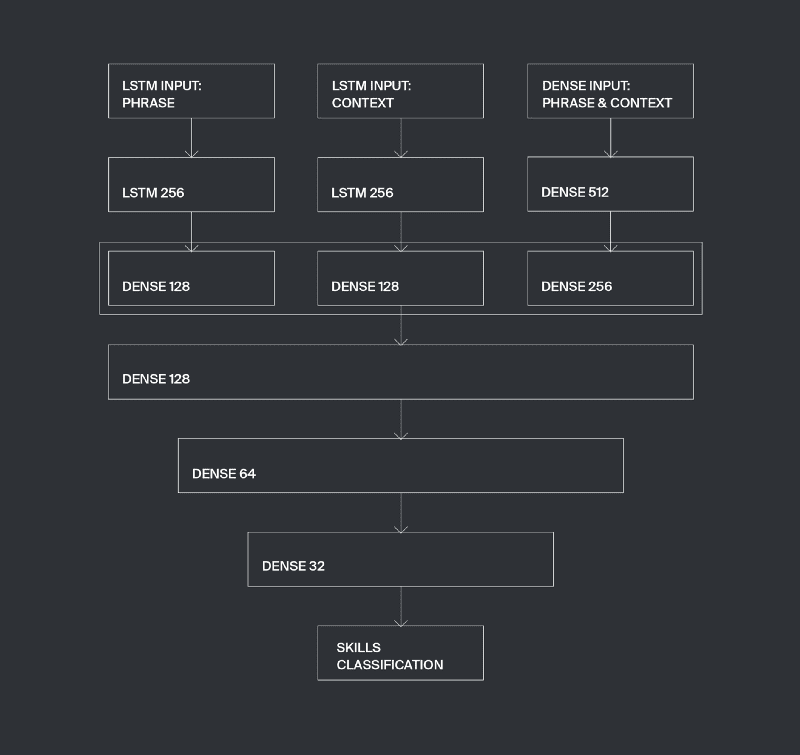
분류(Classification) 작업은 3개의 입력 레이어가 있는 ‘전문기술’ 신경망을 사용하여 수행되며 각 입력 레이어는 데이터의 특수한 클래스를 가질 수 있도록 설계되었습니다. 첫 번째 입력층은 위에서 기술했듯이 임의의 수의 단어를 가질 수 있는 후보 구문의 feature 들을 고려하여 가변 길이 벡터를 취할 수 있게 구성했습니다. 이 feature 벡터는 LSTM 레이어를 통해 처리됩니다.
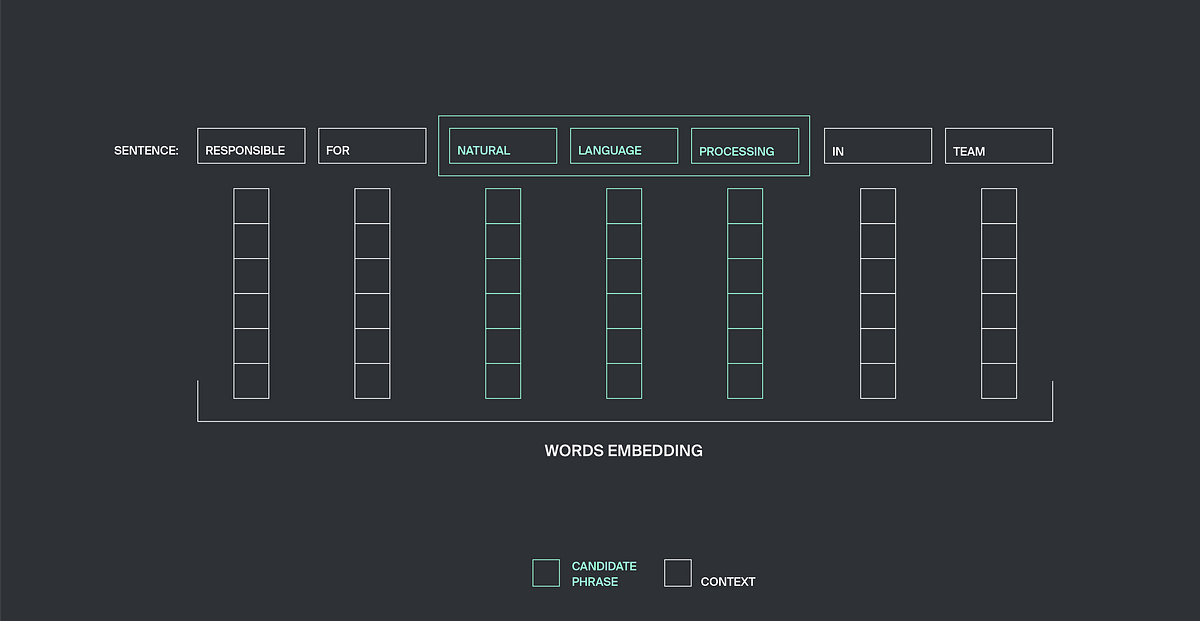
두 번째 입력 레이어에서는 가변 길이 벡터는 컨텍스트 구조 정보를 가져옵니다. 주어진 윈도우 사이즈 n 에 대해서 우리는 후보 구문의 오른쪽에 n 개의 이웃한 단어를 가져오고, 이들 단어의 벡터 표현은 가변 길이 벡터로 연결 되어 LSTM 레이어로 전달됩니다. 우리는 최적의 n = 3 이라는 것을 발견했습니다.
세 번째 입력 레이어는 고정된 길이를 가지며 후보 구민 및 그 문맥에 대한 일반적인 정보를 벡터로 처리합니다. 좀 더 자세히 설명하면, 세 번째 입력 레이어에서 처리하는 정보는 단어 벡터들의 좌표상의 최댓값과 최솟값들입니다. 이 값들은 다른 정보들 사이에서 전체 구문에서 많은 binary feature 들이 사용되었는지 아닌지를 나타내는 값들입니다.
우리는 이 모델 아키텍처를 SkillsExtractor 라고 부르기로 했습니다. 아래를 보세요.
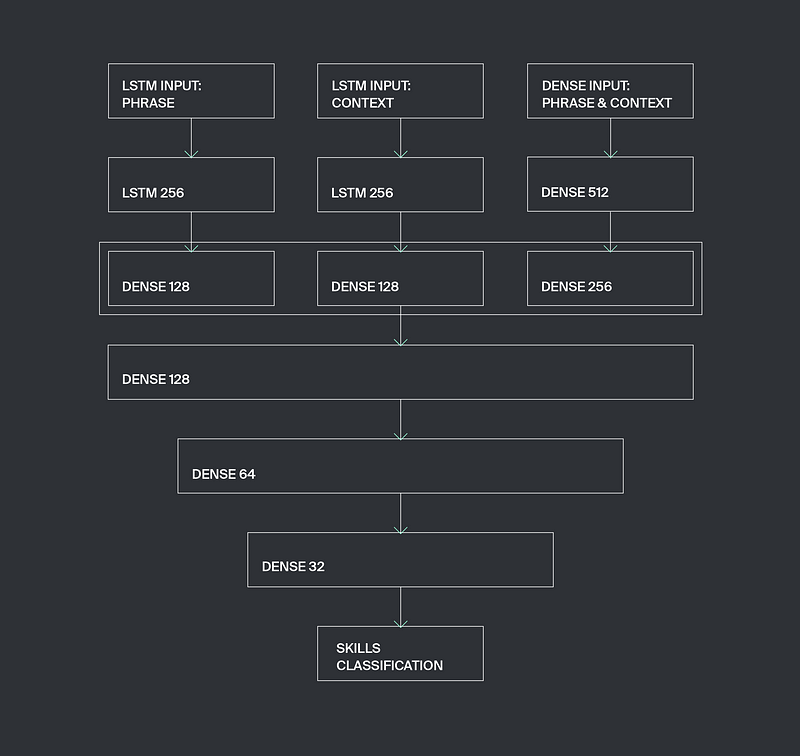
해당 아키텍처의 Keras를 이용한 구현한 코드는 아래와 같습니다.
class SkillsExtractorNN:
def __init__(self, word_features_dim, dense_features_dim):
lstm_input_phrase = keras.layers.Input(shape=(None, word_features_dim))
lstm_input_cont = keras.layers.Input(shape=(None, word_features_dim))
dense_input = keras.layers.Input(shape=(dense_features_dim,))
lstm_emb_phrase = keras.layers.LSTM(256)(lstm_input_phrase)
lstm_emb_phrase = keras.layers.Dense(128, activation='relu')(lstm_emb_phrase)
lstm_emb_cont = keras.layers.LSTM(256)(lstm_input_cont)
lstm_emb_cont = keras.layers.Dense(128, activation='relu')(lstm_emb_cont)
dense_emb = keras.layers.Dense(512, activation='relu')(dense_input)
dense_emb = keras.layers.Dense(256, activation='relu')(dense_emb)
x = keras.layers.concatenate([lstm_emb_phrase, lstm_emb_cont, dense_emb])
x = keras.layers.Dense(128, activation='relu')(x)
x = keras.layers.Dense(64, activation='relu')(x)
x = keras.layers.Dense(32, activation='relu')(x)
main_output = keras.layers.Dense(2, activation='softplus')(x)
self.model = keras.models.Model(inputs=[lstm_input_phrase, lstm_input_cont, dense_input],
outputs=main_output)
optimizer = keras.optimizers.Adam(lr=0.0001)
self.model.compile(optimizer=optimizer, loss='binary_crossentropy')
def fit(self, x_lstm_phrase, x_lstm_context, x_dense, y,
val_split=0.25, patience=5, max_epochs=1000, batch_size=32):
x_lstm_phrase_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_phrase)
x_lstm_context_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_context)
y_onehot = onehot_transform(y)
self.model.fit([x_lstm_phrase_seq, x_lstm_context_seq, x_dense],
y_onehot,
batch_size=batch_size,
pochs=max_epochs,
validation_split=val_split,
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss', patience=patience)])
def predict(self, x_lstm_phrase, x_lstm_context, x_dense):
x_lstm_phrase_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_phrase)
x_lstm_context_seq = keras.preprocessing.sequence.pad_sequences(x_lstm_context)
y = self.model.predict([x_lstm_phrase_seq, x_lstm_context_seq, x_dense])
return y모델 훈련의 결과 중 최상의 결과는 Adam 옵티마이저를 사용, learning rate를 0.0001까지 낮춤을 통해서 얻을 수 있었습니다. 우리는 모델이 두 개의 클래스로 분류하도록 설계했기 때문에 손실함수는 binary crossentropy함수를 사용했습니다. 또한 후보 구문의 feature 벡터에 대한 예측을 형성하면서 동시에 편리함을 위해 교차 검증 및 예측 기능을 사용하여 신경망의 훈련과 자동 정지를 수행하는 적합한 방법을 추가했습니다.
pad_sequence 함수는 feature 시퀀스 리스트를 리스트 내에서 가장 긴 시퀀스와 같은 너비의 2d array로 변환해줍니다. 이 함수를 LSTM 레이어로 이동하는 가변 길이 데이터를 모델 훈련에 필요한 형식으로 가져오기 위해서 사용했습니다.
def onehot_transform(y):
onehot_y = []
for numb in y:
onehot_arr = np.zeros(2)
onehot_arr[numb] = 1
onehot_y.append(np.array(onehot_arr))
return np.array(onehot_y)개체와 컨텍스트의 단어 수가 임의의 개수를 가질 때, 고정된 사이즈의 벡터를 사용하는 것은 합리적인 것처럼 보이지 않습니다. 따라서 임의의 길이의 벡터를 처리하는 RNN 은 여기에 편리하고 아주 자연스러운 해결책이 됩니다. 우리가 테스트해본 결과 고정된 길이의 벡터와 다양한 길이의 벡터를 처리하기 위한 LSTM 레이어를 처리하기 위해 Dense 레이어를 사용하는 것이 최적임을 입증할 수 있었습니다.
LSTM 과 dense의 다양한 조합으로 여러 가지 아키텍처를 실험해보았습니다. 최종 아키텍처 구성 (레이어의 크기와 수) 은 학습 데이터의 최적 사용에 해당하는 cross-validation 테스트에서 최상의 결과를 보여줬습니다. 모델의 튜닝은 학습 데이터셋의 크기를 증가시키는 것과 함께 레이어의 크기와 숫자를 적절히 조정하는 것을 통해 수행할 수 있으며, 동일한 데이터셋으로 레이어 크기와 숫자를 조정하는 것은 모델의 오버피팅으로 이어질 수 있습니다.
Results
| CV | Extracted skills |
|---|---|
| Software engineer on an educational game for schoolers. The game was based on the story of “Tom Sawyer”. The game was developed on Delphi and Java. | Software engineer, 0.999 Delphi, 0.979 Java, 0.974 |
| Teaching a courses on Big Data analytics for bussiness management. Target of the training - overview on big data and predictive modelling - and how the data and analytics can solve business problems. | Big Data analytics, 0.998 predictive modelling, 0.981 analytics, 0.943 bussiness management, 0.926 big data, 0.771 |
| Work with Hadoop and Big Data stack on building data pipelines for streaming and batch processing of the data using Lambda architecture. Product expert for Hadoop and Big Data - including Hive, KNOX and Sqoop. | Lambda architecture, 0.998 Big Data stack, 0.998 building data pipelines, 0.997 Product expert, 0.996 KNOX, 0.992 Hive, 0.982 Sqoop, 0.951 Hadoop, 0.945 Big Data, 0.905 batch processing, 0.828 |
| Developed software for Unix server-side installations of different products. | Unix server-side installations, 0.991 software, 0.979 |
| Teaching programming courses in server side web development using Javascript, Python and MySQL. | server side web development, 0.998 Python, 0.99 Javascript, 0.961 MySQL, 0.949 |
| Responsible for developing software in C++ and Java for Trans Golden Oland operations office. | developing software, 0.996 C++, 0.989 Java, 0.9 |
마무리하며
모델 학습에 사용된 모든 이력서는 IT업계 분야의 이력서였습니다. 우리 모델은 디자인, 금융과 같은 다른 산업에 속한 이력서의 데이터셋에서도 상당히 합리적인 성능을 보여주었습니다. 분명히 완전히 다른 구조와 스타일로 이력서를 처리하면 모델 성능이 저하됩니다. 우리는 또한 ‘전문기술’ 개념에 대한 우리의 이해는 다른 누군가의 이해와 다를 수 있음을 언급하고 싶습니다. 우리 모델에게 있어서 정답을 찾기 어려운 사례 중 하나는 ‘전문기술’을 종종 새로운 회사 이름으로부터 뽑아내는 경우였습니다. 이는 ‘전문기술’ 이 종종 소프트웨어 프레임워크와 동일하기 때문이거나 때로는 사람의 경우도 이것이 회사 이름인지 새로운 JS 프레임워크 또는 Python 라이브러리인지 말하기 어려운 경우도 있었습니다. 그렇지만, 대부분의 경우에서 우리의 모델은 자동 이력서 분류에 유용한 툴로 사용될 수 있으며, 일부 통계적인 방법을 사용하면 임의의 이력서 자료에 대해 광범위한 데이터 사이언스 작업을 해결할 수 있습니다.