참고자료
-
원본 아티클 - Best Data and Big Data Visualization Techniques
연구자들은 시각(vision)이 우리의 감각중 가장 지배적이라는 의견에 동의합니다. 우리가 인식하고 배우고 처리하는 정보의 80-85 %가 시각을 통해 얻게됩니다. 우리가 데이터를 이해하고 해석하려고 할 때 또는 상대적인 중요성을 결정하기 위해 수백 또는 수천 개의 변수들 사이의 관계를 찾고있을 때 더욱 그렇습니다. 중요한 관계를 식별하는 가장 효과적인 방법 중 하나는 고급 분석을 하고 이를 이해하기 쉽게 시각화하는 것입니다.
데이터 시각화는 거의 모든 지식 분야에 적용됩니다. 다양한 분야의 과학자들은 컴퓨터 기술을 사용하여 복잡한 사건을 모델링하고 날씨 패턴, 건강 상태 또는 수학적 관계와 같이 직접 관찰 할 수없는 현상을 시각화합니다.
데이터 시각화는 질적인 이해를 얻는 데 필요한 중요한 도구 및 기술을 제공합니다. 다음 plots은 기본적인 시각화 기술들입니다.
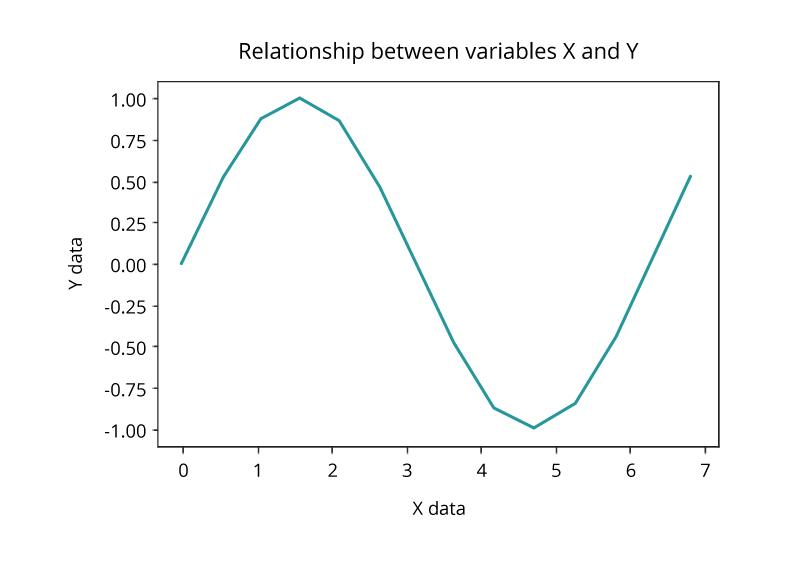
Line Plot
가장 간단한 기법인 선 그래프는 관계(relationship)에 혹은 한 변수가 다른 변수에 대한 종속(dependence) 를 그려주는 데 사용됩니다.두 변수 사이의 관계를 그리려면 단순히 plot 함수를 이용하면 됩니다.
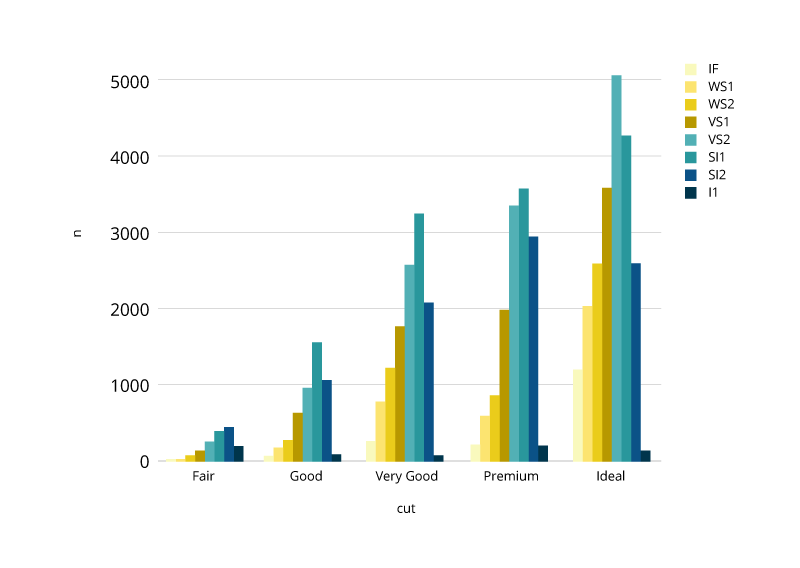
Bar Chart
막대형 차트는 여러 카테고리 또는 그룹의 수량을 비교하는 데 사용됩니다. 카테고리의 값은 막대를 통해 표시되며 세로 막대 또는 가로 막대로 구성 할 수 있으며 각 막대의 길이 또는 높이가 값을 나타냅니다.
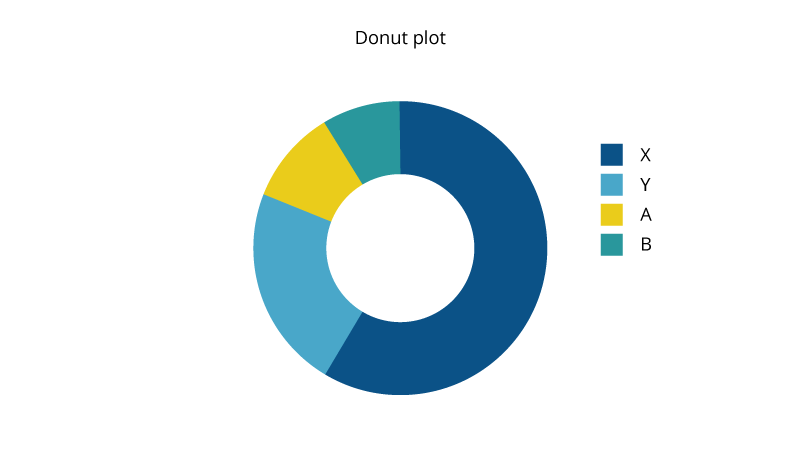
Pie and Donut Charts
파이와 도넛 차트의 가치에 대한 많은 논란이 있습니다. 주로 전체 요소를 비교하는 데 사용되며 제한된 구성 요소가 있을 때와 텍스트 및 백분율이 내용을 설명 할 때 가장 효과적입니다. 그러나, 인간의 눈은 넓이를 추정하고 시각적으로 표현된 각도를 비교하는데 힘들어 하기 때문에 차트를 보고 해석하기 어려울 수 있습니다
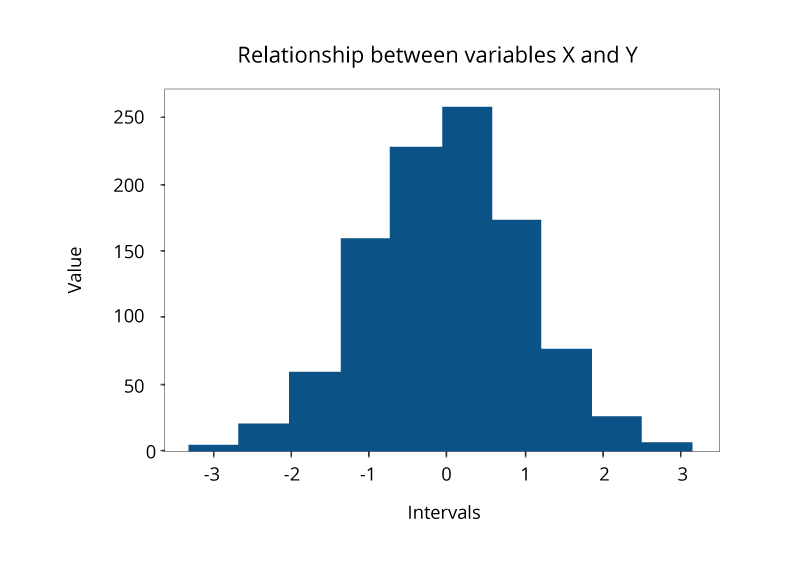
Histogram Plot
히스토그램은 일정 간격 또는 기간 동안 연속 변수의 분포를 나타냅니다. 히스토그램은 머신러닝에서 가장 자주 사용되는 데이터 시각화 기법 중 하나입니다. 히스토그램은 원래 데이터를 ‘bins’라 불리는 간격으로 덩어리로 나눠서(chunking)하여 그립니다. 기본 빈도 분포, 이상치, 왜곡 등을 조사하는 데 사용됩니다.
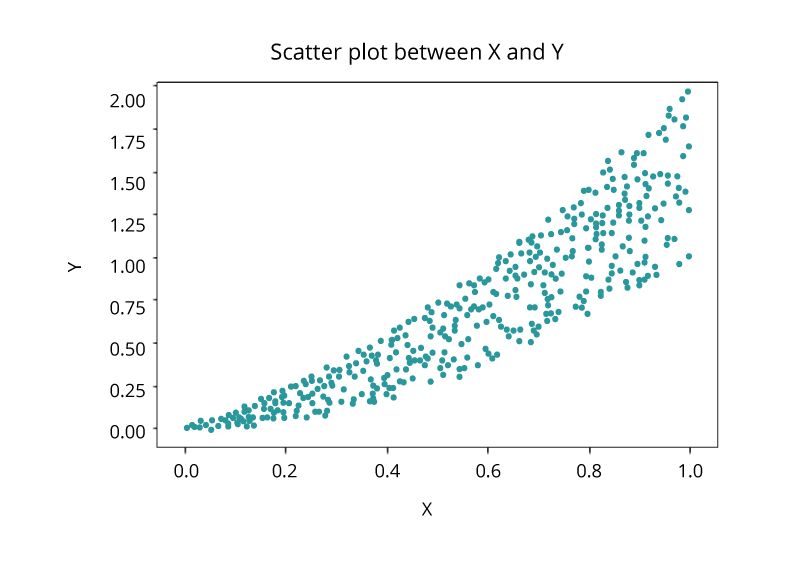
Scatter Plot
또 많이 쓰이는 시각화 기법은 두 데이터 항목의 비례 관계(joint variation)를 나타내는 2차원 plot인 산점도입니다. 각 마커 (점, 사각형 및 +와 같은 기호)는 관측치을 나타냅니다. 마커 위치는 각 관측치 값을 나타냅니다. 두개 이상의 차원(measures)을 지정하면 시각화에 할당된 차원들의 가능한 모든 쌍(pair)을 보여주는 산점도들의 집합인 인 산점도 행렬이 생성됩니다. 산점도는 X와 Y 변수 사이의 관계 또는 상관 관계를 조사하는 데 사용됩니다.
Visualizing Big Data
오늘날 조직에서는 매 분마다 데이터를 생성하고 수집합니다. 빅데이터 (Big Data)라고 알려진 생성된 엄청난 양의 데이터는 정보의 속도, 크기 및 다양성을 고려해야하기 때문에 이를 시각화하는 것은 엄청난 도전(challenges)입니다. 이러한 데이터의 양, 다양성 및 속도는 조직이 효과적인 결정을 내리기 위한 지능으로 이끌기 위해 기술적으로 편안한 영역을 떠나야합니다. 데이터 분석의 핵심 기본 사항을 기반으로하는 새롭고 보다 정교한 시각화 기술은 cardinality(Database에서 엔티티 간 릴레이션을 구성한느 튜플의 수)뿐만 아니라 그러한 데이터의 구조와 기원을 고려합니다.
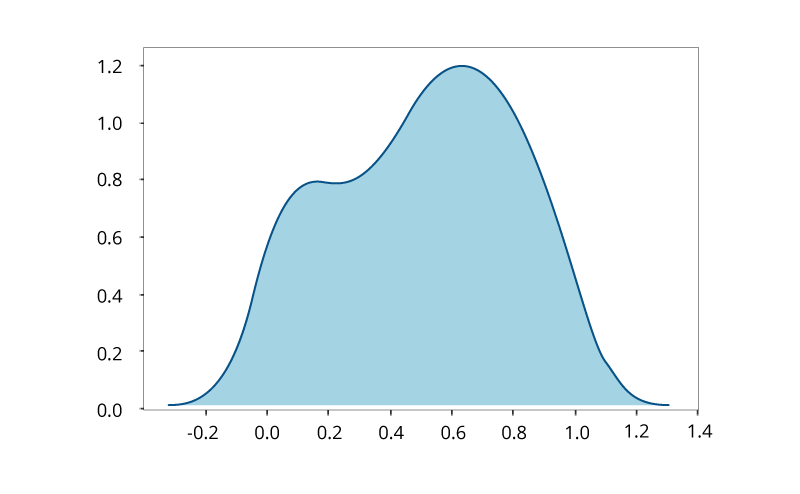
Kernel Density Estimation for Non-Parametric Data
모집단과 기본 데이터 분포에 대한 지식이 없다면, 그러한 데이터를 비모수적 (non-parametric)이라고 부르며, 확률 변수의 확률 분포 함수를 나타내는 Kernel Density Function의 도움으로 가장 잘 시각화됩니다. 데이터의 모수 분포가 이해가되지 않을 때 사용되며 데이터에 대한 가정을 피하기를 원합니다.
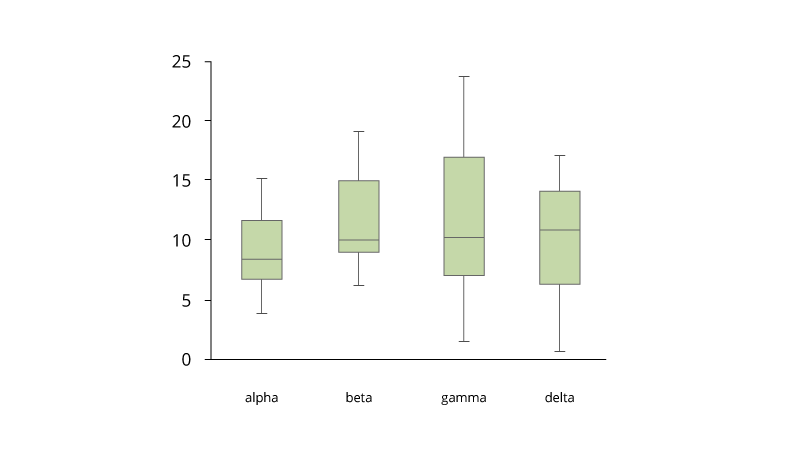
Box and Whisker Plot for Large Data
박스 앤 위스커 플롯은 대용량 데이터의 분포를 보여주고 이상치를 쉽게 볼 수 있습니다. 본질적으로, 데이터 집합의 분포를 요약해주는 다섯 가지 통계량(최솟값, 1/4 분위수, 중앙값, 3/4분위수, 최댓값)를 그래픽으로 표시합니다. 1/4 분위수(25 백분위 수)는 상자의 아래쪽 가장자리로 표시되고 3/4분위수(75 백분위수)는 상자의 위쪽 가장자리로 표시됩니다. 중앙값 (50 백분위수)은 상자를 섹션으로 나누는 중심선으로 표시됩니다. 극값들은 상자 가장자리에서 뻗어 나오는 수염으로 표현됩니다. 상자 플롯은 종종 데이터의 이상치를 이해하는 데 사용됩니다.
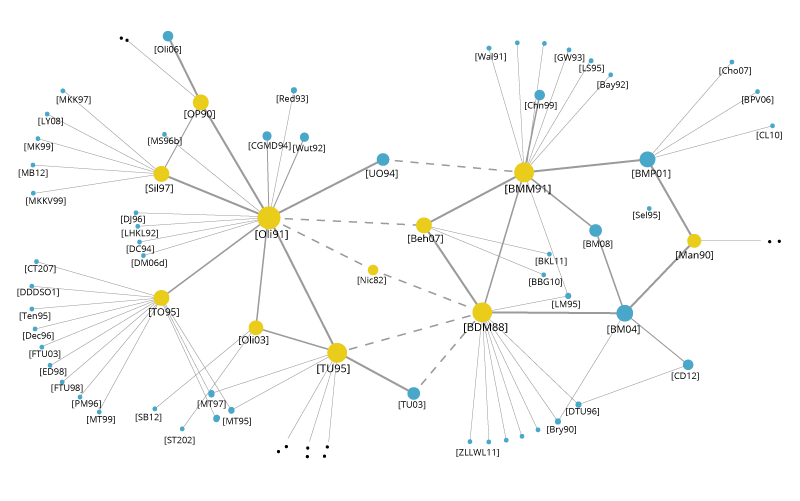
Word Clouds and Network Diagrams for Unstructured Data
반정형 데이터와 비정형 데이터는 새로운 시각화 기법이 필요합니다. Word Cloud 시각화는 Cloud에서 단어의 상대적 크기로 텍스트 본문 내의 단어의 빈도를 나타냅니다. 이 기술은 많이 쓰이는 혹은 적게 쓰이는 단어를 표시하는 방법으로 비정형 데이터에 사용됩니다.

반정형 데이터나 비정형 데이터에 사용할 수있는 또 다른 시각화 기술은 네트워크 다이어그램입니다. 네트워크 다이어그램은 노드 (네트워크 내의 개별 개체)와 관계 (개체간의 관계)로 관계를 나타냅니다. 이들은 소셜 네트워크 분석이나 지리적 영역에서의 제품 판매 매핑과 같은 많은 애플리케이션에 사용됩니다.
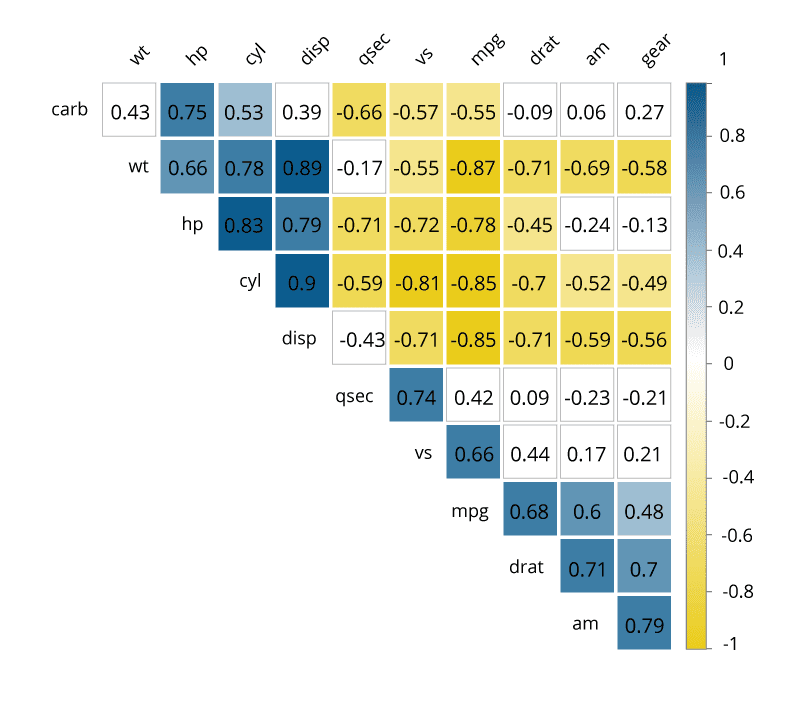
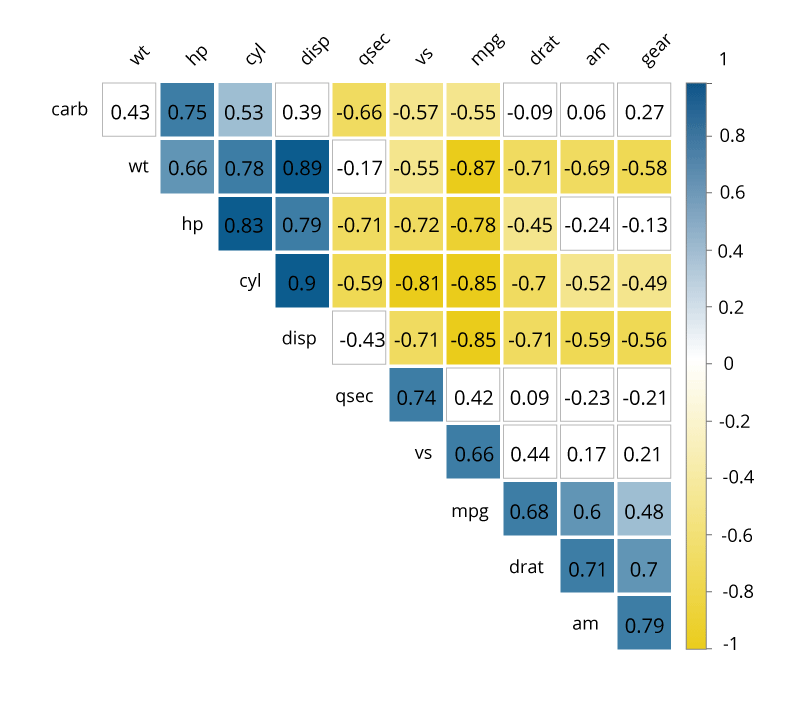
Correlation Matrices
Correlation Matrices을 사용하면 빅데이터와 빠른 응답 시간을 결합하여 변수 간의 관계를 빠르게 식별 할 수 있습니다. 기본적으로 Correlation Matrices은 변수 간의 상관 계수를 나타내는 테이블입니다. 표의 각 셀은 두 변수 간의 관계를 나타냅니다. Correlation Matrices은 데이터를 요약하고, 고급 분석에 대한 입력값 및 고급 분석을 위한 진단 도구로 사용됩니다.
데이터 시각화는 프레젠테이션에 귀중한 부가 요소가 될 수 있으며 데이터를 이해하는 가장 빠른 방법이 될 수 있습니다다. 게다가, 데이터를 시각화하는 과정은 즐겁기도 하고 어려울 수도 있습니다. 그러나, 여러 가지 기법을 이용할 수 있기 때문에 결국 잘못된 도구를 사용하여 정보를 나타내기 쉽습니다. 가장 적절한 시각화 기술을 선택하려면 데이터 그 자체와 데이터의 유형 및 구성, 청중에게 전달하려는 정보 및 시청자가 시각 정보를 처리하는 방법을 이해해야 합니다다. 때로는 간단한 Line plot이 고급 빅데이터 기법을 사용하여 데이터를 시각화하기 위해 드는 시간과 노력을 절약할 수 있습니다. 데이터를 이해하면 숨겨진 가치를 알게 될 것입니다.