원문 아티클 : Attn: Illustrated Attention
아래의 글은 TowardDataScience에 올라온 Raimi bin Karim의 Attn: Illustrated Attention을 번역한 글입니다. 원문 저자의 허락을 받고 번역한 것임을 미리 알려드립니다.
Attn: Illustrated Attention
GIFs를 활용한 기계번역(ex. 구글번역기)에서의 Attention
신경망을 활용한 기계 번역모델(NMT)이 나오기 전 수십 년 동안, 통계기반 기계 번역(Statistical Machine Translation)이 지배적인 모델이었습니다[9]. NMT는 거대한 단일 신경망을 구축하고 훈련합니다. 이러한 방식은 입력 텍스트를 읽고 번역을 출력하는 기계번역의 새로운 접근법입니다. [1].
기계 번역모델의 선구 연구들은 Kalchbrenner and Blunsom (2013), Sutskever et. al (2014) 와 Cho. et. al (2014b)입니다. 여기서 더 익숙한 구조는 Sutskever et. al.의 Sequence-to-Sequence입니다. 이 기사는 seq2seq 구조를 기반으로 하고 어떻게 attention이 작동하는지를 보여줍니다.

seq2seq의 아이디어는 인코더(encoder)와 디코더(decoder)라는 2개의 RNN를 갖는 것입니다: 인코더가 고정된 차원의 벡터를 표현하기 위해 입력단어를 읽고, 디코더가 입력에 따라 다른 RNN를 사용하여 가변 된 차원의 벡터를 출력합니다. (설명은 [5]에서 얻었습니다.)

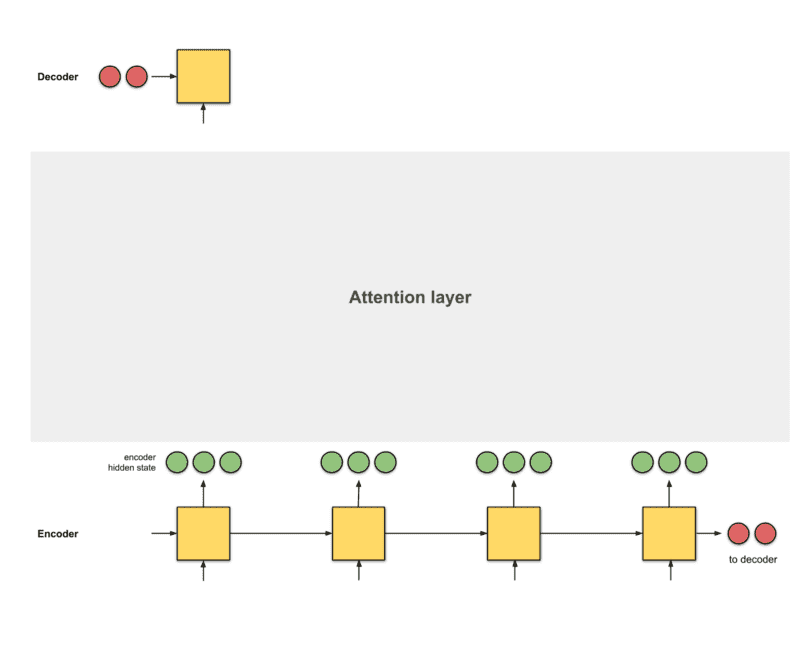
seq2seq의 문제는 디코더가 인코더로부터 수신하는 정보가 인코더의 마지막 hidden state 값이며(첫번째 그림의 두 개의 빨간색 노드), 이는 input 값을 요약한 고정 된 벡터입니다. 위의 그림처럼 보다 긴 input 값이 들어오면, 인코더는 맨 그림과 같은 길이의 고정 된 벡터로 input 값을 요약합니다. 하지만 input 값의 차이가 큼에도 요약한 벡터의 길이가 같은 것은 이상합니다. 이것은 극단적인 망각으로 이어질 수 있습니다. 이 단락에는 100단어가 있습니다. 이 단락을 네가 아는 다른 언어로 바로 번역할 수 있습니까?
만약 우리가 할 수 없다면, 우리는 디코더에도 시키면 안 됩니다. input 값을 하나의 벡터로 표현하는 대신에, 인코더의 시각에 따른 벡터표현을 디코더에 제공하여 더 나은 번역을 할 수 있을까요? 이것이 Attention으로 가는 시작입니다.

attention은 seq2seq의 발전된 모델로, 모든 인코더의 hidden state 값을 디코더에 제공합니다(위 그림의 빨간색 hidden state 값은 제외). 이 설정을 사용하면, 모델은 입력된 문장의 유용한 부분에 집중하는 것이 가능하므로 모델 간의 얼라인먼트(alignment)을 학습할 수 있습니다. 이것은 긴 입력 문장에 효과적으로 대처하는 데 도움이 됩니다. [9].
정의: 얼라인먼트(alignment) 얼라인먼트란 원본 텍스트의 단어를 번역의 해당 단어와 일치시키는 것을 의미합니다. 설명은 링크에서 가져왔습니다.
")
[2]에서 소개된 것처럼 두 가지 attention이 있습니다. 모든 인코더 hidden state를 사용하는 attention을 global attention이라고 합니다. 대조적으로, local attention은 인코더 hidden state의 하위 집합만 사용합니다. 이 기사에서 “attention”이라고 언급된 것은 “global attention”을 의미합니다.
이 기사에서는 애니메이션을 사용하여 attention이 어떻게 작동하는지 요약하여 제공하므로 수학적 표기법이 없이 이해할 수 있습니다. 예시로, 지난 5년 동안 설계된 4개의 NMT 아키텍처를 공유할 것입니다. 나는 또한 몇몇 개념에 직관을 첨가할 것입니다.
목차
- attention: 개요
- attention: 예시
- 요약 부록: 평가 함수
1. attention: 개요
attention을 보기 전에, seq2seq모델을 사용하여 번역(translation) 작업에 대해 보도록 하겠습니다.
직관 : seq2seq 번역자는 시작부터 끝까지 독일어 텍스트를 읽습니다. 끝나면 그는 영어로 단어로 번역되기 시작합니다. 문장이 극단적으로 길다면 그가 초기 부분에서 읽은 것을 잊어버릴 수도 있습니다.
따라서 seq2seq는 간단한 모델입니다. attention 레이어에 대한 단계별 계산은 seq2seq + attention 모델입니다. 이 모델에 대한 간단한 직관이 있습니다.
직관 : seq2seq + attention 번역자는 시작부터 끝까지 키워드을 적어서 독일어 텍스트을 읽은 다음 영어로 번역하기 시작합니다. 각 독일어 단어을 번역하는 동안 그는 작성한 키워드을 사용합니다.
attention은 각 단어에 점수를 할당하여 다른 단어에 초점을 맞 춥니다. 그런 다음 softmaxed 점수를 사용하여 인코더의 hidden state 가중 합을 구해 context 벡터를 얻습니다. attention 레이어의 구현은 4단계로 나눌 수 있습니다.
Step 0: hidden state의 준비
먼저 첫 번째 디코더 hidden state (빨간색)과 사용 가능한 모든 인코더 hidden state (녹색)를 준비합시다. 이 예제에서는 4개의 인코더 hidden state와 현재 디코더 hidden state가 있습니다.

1 단계 : 모든 인코더 hidden state의 점수 얻기
점수 (스칼라)는 평가 함수 (부록 평가 함수 [2] 또는 얼라이먼트 모델 [1]이라고도 함)에 의해 얻어집니다. 이 예제에서, 평가 함수는 디코더와 인코더 hidden state 사이의 내적입니다.
다양한 점수 기능에 대해서는 부록 A를 참조하십시오.

decoder_hidden = [10, 5, 10]
encoder_hidden score
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35위의 코드예시에서 인코더 hidden state [5, 0, 1]에 대해 60의 높은 점수를 얻었습니다. 이것은 변환될 다음 단어가 이 인코더 hidden state의 영향을 크게 받을 것임을 의미합니다.
2 단계 : 모든 점수를 softmax 레이어를 통해 실행하십시오.
우리는 softmaxed 점수 (스칼라)가 1이 되도록 softmax 층에 점수를 둡니다. 이 softmaxed 점수는 attention 분포를 나타냅니다.

encoder_hidden score score^
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0softmaxed 점수 score^을 기반으로 attention 분포는 예상대로 [5, 0, 1]에 놓여 있음을 주목하십시오. 실제로 이 수는 2진수가 아니라 0과 1 사이의 소수값입니다.
3 단계 : 각 인코더 hidden state에 softmaxed 점수를 곱합니다.
각 인코더 hidden state에 softmaxed score (스칼라)를 곱하여 얼라이먼트 벡터 [2] 또는 annotation 벡터 [1]을 얻습니다. 이것은 attention이 이루어지는 메커니즘입니다. ( annotation : Encoder의 hidden state를 의미)

encoder score score^ alignment
---------------------------------[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]여기에서는 [5, 0, 1]을 제외한 모든 인코더 hidden state에 대한 얼라이먼트가 낮은 attention 점수로 인해 0이 되었음을 알 수 있습니다. 즉, 첫 번째로 번역된 단어가 입력 단어와 [5, 0, 1] 가 관련되는 것을 기대할 수 있습니다.
4 단계 : 얼라이먼트 벡터를 합하십시오.
얼라이먼트 벡터는 합쳐져 context 벡터를 생성합니다. context 벡터는 이전 단계의 얼라이먼트 벡터에 대한 집계 정보입니다.

encoder score score^ alignment
---------------------------------[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
context = [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]5 단계 : context 벡터를 디코더에 전달하십시오.
이것이 이루어지는 방식은 아키텍처 설계에 달려 있습니다. 나중에 섹션 2a, 2b 및 2c의 예에서 아키텍처가 디코더에 context 벡터를 사용하는 방법을 살펴볼 것입니다.

이게 전부 입니다! 전체 애니메이션은 다음과 같습니다.

직관 : attention은 실제로 어떻게 작용합니까? 답변 : 역전파(Backpropagation). 역전파는 output이 정답에 가까워지도록 보장하는 데 필요한 모든 작업을 수행합니다. 이는 RNN과 스코어 함수가 있는 경우 해당 스코어 함수에서 가중치를 변경하여 수행됩니다. 이러한 가중치는 인코더 hidden state 및 디코더 hidden state에 영향을 미치고 attention 점수에 영향을 미칩니다.
2. attention: 예시
이전 섹션에서 seq2seq 및 seq2seq + attention 아키텍처를 모두 보았습니다. 다음 하위 섹션에서는 attention을 구현하는 NMT에 대한 세 가지 seq2seq 기반 아키텍처를 더 살펴보겠습니다. 완성을 위해 필자는 BLEU (Bilingual Evaluation Understudy) 점수( - )생성 된 문장을 참조 문장으로 평가하기 위한 표준 척도)를 추가했습니다.
2a. Bahdanau et. al (2015) [1]
이 attention의 구현은 attention의 아버지들의 작품입니다. 저자는 단어 align을 페이퍼의 제목 “Neural Machine Translation by Learning to Jointly Align and Translate”에 사용하고 점수에 직접 영향을 미치는 가중치를 조정하는 것을 의미하였습니다. 다음은 아키텍처에 대해 주의해야 할 사항입니다.
- 인코더는 bidirectional(순방향 + 역방향) gated recurrent unit (BiGRU)입니다. 디코더는 초기 hidden state가 역방향 인코더 GRU (아래 그림에 표시되지 않음)의 마지막 hidden state에서 수정 된 벡터 인 GRU입니다.
- attention 레이어의 스코어 기능은 additive/concat입니다.
- 다음 디코더 단계에 대한 입력은 이전 디코더 시각 단계 (분홍색)의 출력과 현재 시각 단계의 context 벡터 (진한 녹색) 간의 결합입니다.

저자는 WMT’14 English-to-French 데이터 세트에서 BLEU 점수가 26.75를 획득했습니다.
직관 : seq2seq with bidirectional encoder + attention 번역가 A는 키워드를 기록하면서 독일어 텍스트를 읽습니다. 번역가 B (문장을 거꾸로 읽으면서 번역할 수 있는 능력이 있어서 수석 역할을 담당하는 사람)은 키워드를 적어 넣으면서 마지막 단어에서 첫 번째 문장까지 같은 독일어 텍스트를 읽습니다. 이 두 사람은 지금까지 읽은 모든 단어에 대해 정기적으로 토론합니다. 이 독일어 텍스트를 읽은 후, 번역가 B는 토론과 두 키워드가 집어넣은 통합 키워드를 기반으로 독일어 문장을 한 단어씩 영어로 번역해야 합니다. 번역가 A는 순방향 RNN이고, 번역가 B는 역방향 RNN입니다.
2b. Luong et. al (2015) [2]
Effective Approaches to Attention-based Neural Machine Translation의 저자들은 Bahdanau 등에서 아키텍처를 단순화하고 일반화하는 것을 강조했습니다. al. 방법은 다음과 같습니다.
- 인코더는 2 스택 길이의 LSTM (short-term memory) 네트워크입니다. 디코더 또한 같은 아키텍처를 가지며, 디코더의 초기 hidden state는 마지막 인코더 hidden state입니다.
- 그들이 실험 한 점수 함수는 (i) additive/concat, (ii) dot product, (iii) location-based, 그리고 (iv) general. 입니다.
- 현재 디코더 시각 단계로부터의 출력과 현재 시각 단계로부터의 context 벡터 간의 연결은 현재 디코더 시각 단계의 최종 출력(분홍색)을 주기 위해 feed-forward neural network에 공급된다.

WMT’15 English-to-German 데이터 세트에서 BLEU 점수 25.9를 획득했습니다.
직관 : 2-layer stacked encoder + attention 번역가 A는 키워드를 기록하면서 독일어 텍스트를 읽습니다. 마찬가지로 번역가 B (번역가 A보다 수석)은 키워드를 적어 넣는 동시에 같은 독일어 텍스트를 읽습니다. 주니어 번역가 A는 그들이 읽는 모든 단어를 번역자 B에게 보고해야 합니다. 일단 읽고 나면, 두 사람은 그들이 집어넣은 통합 키워드에 기초하여 문장을 영어로 한마디 번역합니다.
2c. Google’s Neural Machine Translation (GNMT) [9]
대부분의 사람이 Google 번역을 어떤 방식으로든 사용해야 했기 때문에 2016년에 구현된 Google의 NMT에 관해 이야기하는 것이 필수적이라고 생각합니다. GNMT는 이전에 우리가 보았던 두 가지 예를 결합한 것입니다(매우 감명받은 자료 [1]).
- 인코더는 8개의 LSTM 스택으로 구성됩니다. 첫 번째는 양방향 (출력이 결합함)이고 나머지 레이어는 연속 레이어의 출력 (세 번째 레이어부터 시작) 사이에 존재합니다. 디코더는 8개의 단방향 LSTM의 개별 스택입니다.
- 사용 된 스코어 함수는 [1])에서와 같이 additive/concat입니다.
- 다시 [1])에서와 같이 다음 디코더 단계에 대한 입력은 이전 디코더 시각 단계 (분홍색)의 출력과 현재 시각 단계의 context 벡터 (진한 녹색) 간의 연결입니다.

WMT’14 English-to-French 데이터 세트에서 BLEU 점수가 38.95였고, WMT’14 English-to-German에서 BLEU 점수가 24.17이었습니다.
직관 : GNMT — seq2seq with 8-stacked encoder (+bidirection+residual connections) + attention 8명의 번역자가 A, B…. H로 시작하여 아래에서 위로 열(column)에 있습니다. 모든 번역자는 같은 독일어 텍스트를 읽습니다. 모든 단어에서 번역가 A는 자신의 연구 결과를 번역가 B와 공유하고 이를 개선하고 이를 번역가 C와 공유합니다. 번역가 H에 도달할 때까지 이 과정을 반복합니다. 또한, 독일어 텍스트를 읽는 동안 번역가 H는 그가 아는 내용과 그가 받은 정보에 따라 관련 키워드를 기록합니다. 일단 모든 사람이 이 영어 텍스트를 읽는다면, 번역가 A는 첫 단어를 번역해야 한다고 말합니다. 먼저 그는 리콜을 시도한 다음 번역가 B와 답변을 공유하고 번역가 C와의 답변을 공유합니다. 번역가 H에 도달할 때까지 이 작업을 반복합니다. 번역가 H는 그가 작성한 키워드와 그가 얻은 답을 바탕으로 첫 번째 번역 단어를 작성합니다. 우리가 번역을 끝낼 때까지 이것을 반복하십시오.
요약
다음은 이 기사에서 본 모든 아키텍처에 대한 간단한 요약입니다.
- seq2seq
- seq2seq + attention
- seq2seq with bidirectional encoder + attention
- seq2seq with 2-stacked encoder + attention
- GNMT — seq2seq with 8-stacked encoder (+bidirection+residual connections) + attention
다음 저서에서는 self attention의 개념과 이것이 Google의 Transformer 및 Self-Attention Generative Adversarial Network (SAGAN)에서 어떻게 사용되었는지에 대해 알아볼 것입니다.
부록 : 점수함수
아래는 Lilian Weng이 모은 점수 함수 중 일부입니다. Additive/concat 및 dot product가 이 기사에서 언급되었습니다. 내적 연산 (내적, 코사인 유사성 등)과 관련된 점수 함수의 기본 개념은 두 벡터 간의 유사성을 측정하는 것입니다. feed-forward neural network 스코어 함수의 경우, 아이디어는 모델이 변환과 함께 정렬 가중치를 학습하도록 하는 것입니다.


참고
[1] Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et. al, 2015)
[2] Effective Approaches to Attention-based Neural Machine Translation (Luong et. al, 2015)
[3] Attention Is All You Need (Vaswani et. al, 2017)
[4] Self-Attention GAN (Zhang et. al, 2018)
[5] Sequence to Sequence Learning with Neural Networks (Sutskever et. al, 2014)
[6] TensorFlow’s seq2seq Tutorial with Attention (Tutorial on seq2seq+attention)
[7] Lilian Weng’s Blog on Attention (Great start to attention)
연관된 딥러닝 기사
Line-by-Line Word2Vec Implementation (on word embeddings)
Step-by-Step Tutorial on Linear Regression with Stochastic Gradient Descent
10 Gradient Descent Optimisation Algorithms + Cheat Sheet
Counting No. of Parameters in Deep Learning Models
Derek, William Tjhi, Yu Xuan, Ren Jie, Chris, Serene에게 이 기사에 대한 아이디어, 제안 및 수정을 해주셔서 감사드립니다.
트위터 혹은 Linkedin에서 나를 따라 다니며 AI 및 Deep Learning에 관한 기사와 데모를 참조하십시오. raimi.bkarim@gmail.com을 통해 나에게 연락할 수도 있습니다.
Ren Jie Tan, Yu Xuan Tay, and Derek Chia에게 감사를 전합니다.